A.I. PRIME - Article
A CDO's Checklist for Scaling AI from Pilot to Production
Learn the critical governance, infrastructure, and change management strategies CDOs need to scale AI automation solutions successfully across enterprises.
You've successfully piloted an AI automation solution. Your team saw promising results - faster processing times, reduced manual work, improved accuracy. Now comes the harder part: scaling that pilot across multiple business units, geographies, and use cases without losing control or burning through your budget. This is where many organizations stumble. They move too fast without proper governance, they lack the technical infrastructure to support production workloads, or they fail to measure what actually matters. The difference between a successful scale and a failed rollout often comes down to one thing: preparation. This checklist will guide you through the critical decisions and implementations required to move from proof-of-concept to enterprise-wide scaling automation solutions with predictable outcomes.
Establish Governance Frameworks Before You Scale
Governance isn't a constraint on AI adoption - it's the foundation that makes scaling possible. Without clear governance, you'll face decision paralysis, compliance violations, and teams working at cross-purposes. The first step is defining who owns what. Your governance framework should clarify decision rights: who approves new AI initiatives, who manages data access, who monitors for bias and drift, and who handles exceptions when the AI makes mistakes. Learn more in our post on Scale AI from Pilot to Production: A CDO's Essential Checklist.
Start by creating an AI governance committee that includes representation from legal, compliance, operations, technology, and the business units you're scaling into. This committee should meet regularly to review new automation proposals, audit existing deployments, and address escalations. Document your governance policies in a central repository that's accessible to all stakeholders. These policies should cover model validation requirements, data quality standards, performance thresholds, and escalation procedures.
Governance enables speed, not the opposite. Organizations with clear AI governance policies can deploy new automations faster because they've already answered the hard questions about risk, compliance, and accountability.
One critical governance element is establishing clear policies around data access and usage. When you scale AI across business units, you're often combining data from multiple sources. Define what data can be used for model training, how long data is retained, who can access it, and how you'll handle sensitive information like personally identifiable data or trade secrets. This becomes especially important if you're operating across multiple geographies with different regulatory requirements.
Another essential component is bias monitoring and fairness audits. Before you scale, define what fairness means for your specific use cases. For hiring automation, this might mean ensuring equal representation across demographic groups. For credit decisions, it might mean monitoring for disparate impact. Build these checks into your production monitoring infrastructure from day one, not as an afterthought.
Design Scalable Architecture and Infrastructure
Your pilot probably ran on a single machine or a small cluster with manual workflows and point-to-point integrations. Production at scale requires a different approach. You need architecture that can handle increased volume, integrate with multiple systems, maintain high availability, and support governance requirements. This is where many organizations realize their pilot infrastructure won't work at scale. Learn more in our post on From Pilot to Production: Your 90-Day Agentic AI Deployment Blueprint.
Start with a clear separation between your AI/ML infrastructure and your operational infrastructure. Your ML infrastructure should handle model training, validation, and deployment. Your operational infrastructure should handle inference (running the model on new data), data pipelines, monitoring, and logging. These often have different scaling characteristics and different operational requirements. Trying to run everything on the same infrastructure creates bottlenecks and makes it harder to troubleshoot problems.
For the operational infrastructure, design with event-driven architecture in mind. Rather than having batch processes that run on a schedule, set up event streams that trigger automation workflows in real time. When a new customer record is created, an event fires and your AI-driven lead scoring agent starts its analysis. When a support ticket is submitted, an event triggers your automation to classify it and route it appropriately. This approach scales better than batch processing and provides faster response times for business stakeholders.
Implement a data orchestration layer that manages data movement between systems. Your AI models need clean, consistent data from multiple sources - customer databases, transaction systems, external data providers, and more. Rather than having each automation team build their own data pipelines, create a central data orchestration platform that other teams can plug into. This reduces duplication, improves data quality, and makes governance easier to enforce.
Plan for multi-region deployment early if you operate across geographies. This isn't just about resilience - it's about compliance and performance. Some regulations require data to stay within specific regions. Your users expect low latency. Design your architecture to support regional deployments from the start, even if you only deploy to one region initially. This makes future expansion much simpler.
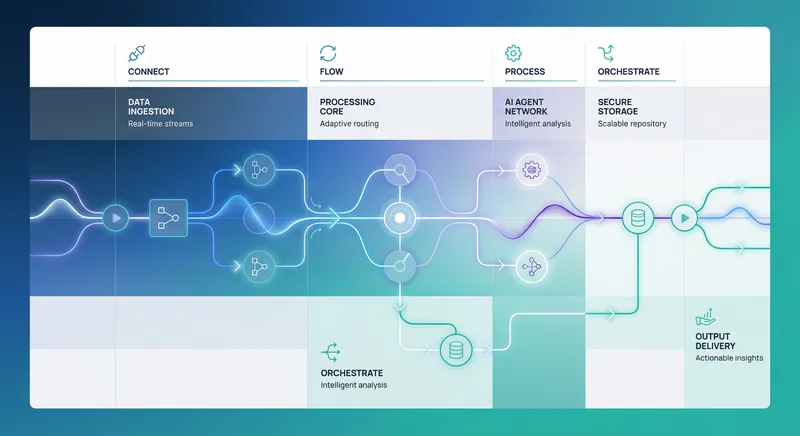
Implement SRE Practices and Performance SLAs
Site Reliability Engineering (SRE) practices are essential for maintaining production systems at scale. SRE brings together software engineering and operations to build systems that are reliable, scalable, and maintainable. For AI automation systems, this is critical because failures can cascade across multiple business units and have direct financial impact. Learn more in our post on Rapid Deployment Playbooks: How to Move AI Automation from Pilot to Production in 90 Days.
Start by defining clear Service Level Objectives (SLOs) for each automation. An SLO is a target for system performance and reliability. For example, your lead scoring automation might have an SLO of 99.5% availability and 95th percentile latency of under 2 seconds. Your invoice processing automation might have an SLO of 99.9% availability with end-to-end processing completing within 4 hours. These SLOs should be based on business impact, not technical convenience. If your system being down for 10 minutes costs your business $100,000 in lost sales, you need higher availability than if the cost is $1,000.
Once you've defined SLOs, establish SLIs (Service Level Indicators) - the actual metrics you'll measure. For availability, this might be the percentage of requests that complete successfully. For latency, it's the response time at various percentiles. For accuracy, it might be the percentage of predictions that match human review or business outcomes. Make sure you're measuring things that actually matter to the business, not just technical metrics.
Implement comprehensive monitoring and alerting from day one. You should track system health metrics (CPU, memory, disk, network), application metrics (request rate, error rate, latency), and business metrics (automation accuracy, cost per transaction, business outcome). Set up alerts that notify the right people when metrics deviate from expected ranges. But be careful not to create alert fatigue - too many alerts means teams start ignoring them.
The best time to define SLOs and set up monitoring is before you go to production, not after you've had an outage. Reactive monitoring is expensive and stressful. Proactive monitoring prevents problems.
Establish a blameless postmortem process for when things go wrong. When an automation fails or performs poorly, conduct a thorough investigation focused on understanding what happened and how to prevent it in the future, not on assigning blame. Document the root cause, the timeline of events, and the corrective actions. Share these learnings across teams so everyone benefits from each incident.
Plan for graceful degradation. Your AI systems won't always work perfectly. When they fail, what should happen? For some use cases, you might want to fall back to a human review process. For others, you might want to queue the work for later processing. For others, you might want to make a conservative decision (e.g., reject a credit application rather than approve it with uncertain data). Design these fallback paths before you go to production.
Manage Change Across the Organization
Technology is only part of scaling AI automation. The bigger challenge is organizational change. When you automate a process, you're changing how people work. Some people will see this as a threat to their job. Others will resist because they've built expertise in the old way of working. Without proper change management, even technically perfect automation will fail because people won't use it or will find ways to work around it.
Start change management early, ideally during the pilot phase. Identify the teams whose work will be affected by the automation. Involve them in designing the solution, not just implementing it. When people have input into how automation works, they're more likely to support it. They also provide valuable insights about edge cases and exceptions that technical teams might miss.
Create clear communication plans that explain what's changing, why, and how it will affect different roles. For some people, automation means their job is eliminated. Be honest about this and provide transition support - retraining, placement assistance, or severance as appropriate. For others, automation means their job changes significantly. They might move from doing routine data entry to reviewing automation decisions and handling exceptions. Help them understand the new role and develop the skills they need.
Build adoption incentives into your rollout plan. Don't just tell teams they have to use the new automation. Show them how it makes their work easier, faster, or more interesting. Celebrate early wins and share success stories. When team A sees team B getting faster turnaround times or fewer escalations after implementing automation, they'll be more eager to adopt it themselves.
Implement training programs that go beyond technical documentation. Create hands-on workshops where people can practice using the automation. Pair experienced users with new users during the early rollout. Establish communities of practice where automation users can share tips and troubleshoot problems together. Make training ongoing, not just a one-time event at launch.
Create feedback mechanisms that let teams report problems and suggest improvements. When you scale across multiple business units, you'll discover issues and opportunities that your central team didn't anticipate. Establish a clear process for teams to report these and have them addressed. This shows you're listening and creates a sense of ownership across the organization.
Measure adoption metrics alongside technical metrics. How many teams are using the automation? How frequently? Are they using it for the intended use cases or finding creative new applications? Are adoption rates increasing or plateauing? If adoption is slower than expected, dig into why. It might be a technical issue that needs fixing, or it might be a change management issue that needs different approaches.
Establish Measurement Frameworks and ROI Tracking
You can't improve what you don't measure. Before you scale, establish a comprehensive measurement framework that tracks the impact of your AI automation across multiple dimensions. This framework should include financial metrics, operational metrics, quality metrics, and strategic metrics.
Financial metrics are often the easiest to justify to leadership. How much is the automation saving in labor costs? What's the cost per transaction before and after automation? What's the payback period on your investment? Be rigorous about these calculations. Don't count savings that come from people being reassigned to other work if that work wasn't generating value before. Don't count savings from headcount reduction if you're not actually reducing headcount. Conservative financial metrics are more credible than optimistic ones.
Operational metrics measure how the automation performs. How many transactions are processed? What's the error rate? How long does processing take? How many exceptions require human review? These metrics help you understand whether the automation is working as designed and identify areas for improvement. Track these metrics over time to see if performance improves as the system learns and teams get better at using it.
Quality metrics measure the accuracy and reliability of the automation. For a document classification automation, this might be the percentage of documents classified correctly. For a lead scoring automation, it might be the correlation between scores and conversion rates. For a customer service automation, it might be customer satisfaction with automated responses. These metrics help you understand whether the automation is actually making better decisions than humans would.
Strategic metrics measure whether the automation is helping achieve broader business goals. Is it improving customer experience? Helping you serve customers faster? Enabling your team to take on more complex work? Reducing risk? These metrics often take longer to show impact but are ultimately what justify continued investment in automation.
The most important metric is the one that matters to your business. If your goal is to reduce costs, measure cost reduction. If your goal is to improve customer experience, measure customer satisfaction. Don't get distracted by metrics that look good but don't actually drive business value.
Implement real-time dashboards that show these metrics to stakeholders. Different stakeholders care about different metrics - executives care about ROI, operations teams care about volume and error rates, quality teams care about accuracy. Create dashboards tailored to each audience. Make these dashboards easily accessible so people can check on progress anytime.
Establish baseline metrics before you scale. Measure how the process worked before automation. How long did it take? What was the error rate? What did it cost? Then measure the same metrics after automation. The difference is your impact. Without baselines, it's hard to prove that the automation actually improved things.
Plan for measurement at scale. When you pilot with a single team processing a few hundred transactions per week, measurement is straightforward. When you scale to multiple teams processing hundreds of thousands of transactions per week, measurement becomes more complex. You need automated data collection and analysis, not manual spreadsheets. Build this infrastructure as part of your scaling plan.
Create a Pilot-to-Production Checklist
As you prepare to scale, use this checklist to ensure you've addressed all critical areas. This isn't meant to be exhaustive - every organization will have additional items specific to their situation - but it covers the main categories that determine success or failure when scaling automation solutions.
- Governance and compliance: Define decision-making authority, establish policies for data access and model validation, create bias monitoring procedures, ensure compliance with relevant regulations
- Architecture and infrastructure: Design scalable data pipelines, implement event-driven workflows, establish data orchestration layer, plan for multi-region deployment, document system architecture
- SRE and operations: Define SLOs and SLIs for each automation, implement comprehensive monitoring and alerting, establish incident response procedures, plan for graceful degradation, create runbooks for common operational tasks
- Change management: Identify affected teams, create communication plans, develop training programs, establish feedback mechanisms, measure adoption metrics
- Measurement and ROI: Establish baseline metrics, define success criteria, implement real-time dashboards, plan for continuous measurement, document expected ROI
- Security and risk: Conduct security assessments, implement access controls, establish data protection procedures, plan for audit requirements, create disaster recovery plans
- Team and skills: Assess current team capabilities, identify skill gaps, plan hiring or training, establish centers of excellence, create career paths for automation specialists
- Vendor and tools: Evaluate technology options, plan integration approaches, establish vendor management processes, negotiate contracts with scalability in mind
- Timeline and resources: Create realistic project plan, allocate sufficient resources, identify dependencies, establish milestones, plan for contingencies
- Stakeholder alignment: Secure executive sponsorship, align with affected business units, establish steering committee, create communication cadence, manage expectations

Common Pitfalls to Avoid When Scaling
Learning from others' mistakes can save you significant time and resources. Here are the most common pitfalls we see organizations encounter when scaling AI automation, and how to avoid them.
The first pitfall is scaling too fast without proper governance. Teams get excited about automation results and want to deploy everywhere immediately. But without governance frameworks in place, you quickly end up with inconsistent implementations, compliance issues, and data quality problems. The solution is to go a bit slower initially while establishing governance, knowing that this foundation will actually accelerate your long-term scaling.
The second pitfall is underestimating change management. Technology teams often assume that if they build it, people will use it. But automation changes how people work, and people naturally resist change. Without proper change management, adoption stalls. The solution is to invest in change management from the beginning, treating it as equally important as the technical work.
The third pitfall is poor measurement. Many organizations scale automation without establishing clear baselines or success metrics. Then they can't prove whether the automation actually worked. The solution is to define metrics before you scale and implement automated measurement systems that track performance continuously.
The fourth pitfall is infrastructure that doesn't scale. A pilot might run fine on a single server, but when you scale to production volume, you hit bottlenecks. The solution is to design architecture for scale from the beginning, even if you don't need all that capacity initially. It's much easier to scale a well-designed system than to redesign a system that's already in production.
The fifth pitfall is insufficient monitoring and alerting. You can't manage what you don't see. Without proper monitoring, problems go undetected until they cause business impact. The solution is to implement comprehensive monitoring before you go to production, with alerts configured to notify the right people when issues occur.
The sixth pitfall is ignoring edge cases and exceptions. Your pilot probably handled the happy path well, but production reveals all the edge cases. Orders with unusual characters in the customer name. Documents in unexpected formats. Customers with unusual transaction patterns. The solution is to plan for exceptions explicitly, deciding how the automation will handle them rather than assuming they won't occur.
Building a Center of Excellence for Scaling Automation
As you scale AI automation across your organization, consider establishing a Center of Excellence (CoE) - a dedicated team that develops standards, best practices, and tools for automation across the enterprise. A CoE accelerates scaling by preventing teams from reinventing the wheel and ensures consistency in how automation is implemented.
Your CoE should include people from multiple disciplines: data scientists who understand model development, engineers who can build scalable infrastructure, operations specialists who understand production systems, compliance experts who understand governance requirements, and change management specialists who understand organizational adoption. This cross-functional team becomes the hub that other teams connect to as they implement automation.
The CoE should develop and maintain several key assets. First, a platform or set of tools that teams can use to implement automation without building everything from scratch. Second, reusable components like data connectors, model templates, and monitoring dashboards. Third, documented standards and best practices for how automation should be implemented. Fourth, training and certification programs that ensure teams have the skills needed to implement automation properly.
The CoE should also serve as the hub for knowledge sharing. Establish regular forums where teams implementing automation can share learnings, discuss challenges, and collaborate on solutions. Create a repository of case studies and lessons learned that other teams can reference. Celebrate successes and help teams learn from failures.
Importantly, the CoE shouldn't be a bottleneck. It should enable teams to move faster, not slower. This means providing self-service tools and clear documentation so teams can implement automation without waiting for CoE approval on every decision. The CoE should focus on governance, standards, and support rather than trying to control every implementation.
Preparing for Continuous Improvement and Evolution
Scaling AI automation isn't a one-time project - it's the beginning of continuous evolution. Your automation will need to improve over time as business requirements change, new data becomes available, and you learn what works. Build this continuous improvement mindset into your scaling plan.
Establish feedback loops that capture insights from production. When automation makes mistakes, capture those examples so you can use them to improve the model. When users find ways to work around the automation, understand why and adapt the automation to better fit their needs. When business processes change, update the automation accordingly. This requires systems and processes for continuous feedback and improvement, not just one-time deployment.
Plan for model retraining and updating. Your models will degrade over time as the world changes. Customer behavior shifts. New competitors emerge. Regulations change. Your models need to be retrained periodically with new data to maintain accuracy. Build this into your operational processes - it's not a special project, it's ongoing work.
Invest in explainability and interpretability. As you scale automation, you'll need to explain decisions to stakeholders, regulators, and customers. Build systems that can explain why the automation made a particular decision. This is especially important for high-stakes decisions like credit approvals, hiring, or healthcare recommendations.
Plan for new use cases. Once you've established the foundation for scaling automation, teams will discover new opportunities. Create processes for evaluating and prioritizing new automation opportunities. Build templates and tools that make it easier to implement new automations. This is where your initial investment in governance, infrastructure, and change management pays off - new automations can be deployed much faster because you've already solved the hard problems.
Conclusion
Scaling AI automation from pilot to production is fundamentally different from running a pilot. It requires attention to governance, architecture, operations, change management, and measurement that many organizations underestimate. The organizations that succeed at scale are those that treat these areas as seriously as they treat the technology itself.
This checklist provides a roadmap for your scaling journey. Start by establishing governance frameworks that clarify decision-making and compliance requirements. Design architecture that can handle production volume and complexity. Implement SRE practices and monitoring that keep your systems reliable. Invest in change management that brings your organization along. Establish measurement frameworks that prove impact. Avoid common pitfalls by learning from others' experiences. Build a center of excellence that accelerates scaling across your organization. Plan for continuous improvement and evolution.
At A.I. PRIME, we help founder-led B2B teams automate repetitive tasks in support, sales, and operations through rapid, measurable AI-driven automation. Our fixed 14-day engagement delivers working automation workflows that integrate with your existing systems and drive operational efficiency from day one. We understand the complexity of scaling automation solutions across business units with predictable outcomes. Our approach combines workflow design, agent deployment, and continuous enablement to ensure your automation delivers measurable results.
If you're preparing to scale AI automation across your operations, we'd welcome the opportunity to discuss your specific situation. We can help you assess your readiness, identify gaps in your current approach, and develop a customized automation strategy that drives measurable operational efficiency. Whether you need help with governance frameworks, workflow design, change management, or measurement systems, we have the expertise to guide you. Reach out to discuss how we can accelerate your automation scaling while managing risk and ensuring sustainable outcomes.
Next step
Book the Opportunity Sprint


