A.I. PRIME - Article
Data Orchestration Best Practices for Predictive Scoring Loops
Discover how data orchestration powers reliable predictive scoring loops with resilient pipelines, feature stores, and governance best practices.

Predictive scoring models are only as good as the data flowing through them. Yet many B2B teams struggle with fragmented pipelines, stale features, and governance blind spots that undermine their AI investments. When data arrives late, incomplete, or misaligned with business logic, scoring loops fail silently - and revenue opportunities slip away. The difference between a high-performing predictive system and one that disappoints often comes down to one critical factor: data orchestration.
Data orchestration is the backbone of any reliable predictive scoring system. It's the engineering discipline that ensures clean, timely, and contextually relevant data reaches your models exactly when they need it. For founder-led teams and small operators deploying AI-driven workflows and autonomous agents, orchestration isn't just a technical detail - it's a strategic capability that directly impacts ROI, decision velocity, and competitive advantage.
In this guide, we'll explore the engineering and governance practices that keep predictive scoring loops performing at scale. You'll learn how to design resilient data pipelines, implement feature stores that enable rapid model iteration, navigate streaming versus batch trade-offs, and establish lineage practices that prove data quality to stakeholders. Whether you're building your first closed-loop AI system or scaling an existing one, these best practices will help you eliminate data silos and accelerate time-to-value.
Understanding Data Orchestration in the Context of Predictive Scoring
Data orchestration refers to the automated coordination and management of data workflows across multiple systems, tools, and teams. In the context of predictive scoring, it's the engine that moves raw signals from operational systems into engineered features, feeds those features into models at inference time, and captures outcomes to close the loop for continuous improvement. Learn more in our post on Data Orchestration Best Practices to Power Predictive Scoring Loops.
Many organizations treat data orchestration as a plumbing problem - "get data from point A to point B." But that mindset leaves significant value on the table. Orchestration is actually a strategic capability that determines whether your predictive models can adapt to changing business conditions, whether you can trust their outputs enough to automate decisions, and whether you can explain those decisions to stakeholders or regulators.
Consider a typical predictive scoring scenario: a B2B SaaS company wants to identify high-intent leads in real time and route them to sales agents. The scoring model needs dozens of features - behavioral signals from web analytics, firmographic data from third-party enrichment, historical transaction patterns, and engagement history. These data sources operate on different schedules, have different latency requirements, and live in different systems. Without orchestration, building and maintaining this pipeline becomes a manual, error-prone nightmare. With orchestration, it becomes a governed, repeatable process.
Over 40% of workers spend at least a quarter of their workweek on data collection and entry tasks. Orchestration automates these repetitive workflows, freeing teams to focus on strategy and insights instead of manual data wrangling.
The real power of orchestration emerges when you scale. As you deploy more models, add new data sources, and increase inference frequency, the complexity of managing dependencies, error handling, and data quality grows exponentially. A well-designed orchestration framework absorbs that complexity and lets your team focus on model innovation rather than firefighting data issues.
Building Resilient Data Pipelines for Predictive Models
A resilient data pipeline is one that continues to deliver accurate, timely data even when upstream systems fail, data quality degrades, or unexpected patterns emerge. For predictive scoring, resilience isn't optional - it's essential. A scoring model that returns stale predictions or crashes when a data source is unavailable can damage customer relationships and erode trust in your AI systems. Learn more in our post on Predictive Scoring Loops: Prioritize Cases and Reduce MTTR in 14 Days.
Pipeline Architecture Principles
Start with clarity on your data flow. Map out every source system, transformation step, and destination. Document which systems are critical path (failures block scoring) and which are optional enrichments (failures degrade quality but don't stop the process). This distinction shapes your architecture decisions.
Use idempotent transformations wherever possible. An idempotent operation produces the same result whether it runs once or multiple times. This property is crucial because retries are inevitable in distributed systems. If your feature engineering logic isn't idempotent, retrying a failed batch job could double-count transactions or create duplicate records.
Implement dead letter queues and error handling paths. When a record fails validation or a transformation step encounters unexpected data, route it to a quarantine area where it can be investigated without blocking the pipeline. Log the original data, the error message, and the timestamp. This creates a feedback loop for data quality improvement.
Design for graceful degradation. If an optional enrichment source becomes unavailable, your pipeline should continue with the core features and mark those records as "enrichment incomplete" rather than failing entirely. This lets downstream systems make informed decisions about whether to score the record with missing features or hold it for retry.
Monitoring and Alerting
You can't maintain a resilient pipeline without visibility. Implement monitoring that tracks not just technical metrics (latency, throughput, error rates) but also data quality metrics that matter to the business.
Key metrics to monitor include:
- Record completeness - percentage of records with all expected fields populated
- Freshness - how recently the data was updated relative to when it's used
- Distribution shifts - unexpected changes in feature value ranges or patterns that might indicate upstream data issues
- Null rates - sudden increases in missing values for critical fields
- Cardinality - unexpected growth in unique values that might indicate data corruption
Set up alerting rules that trigger when these metrics deviate from expected baselines. Alert thresholds should be tiered: warnings for gradual degradation, critical alerts for immediate failures that block scoring. Route critical alerts to on-call engineers immediately; log warnings for review in daily standup meetings.
Implement circuit breakers that automatically disable downstream consumers when data quality falls below thresholds. Rather than propagating bad data through your system, a circuit breaker pauses consumption and alerts the team. This prevents scoring models from ingesting corrupted features and making bad predictions.
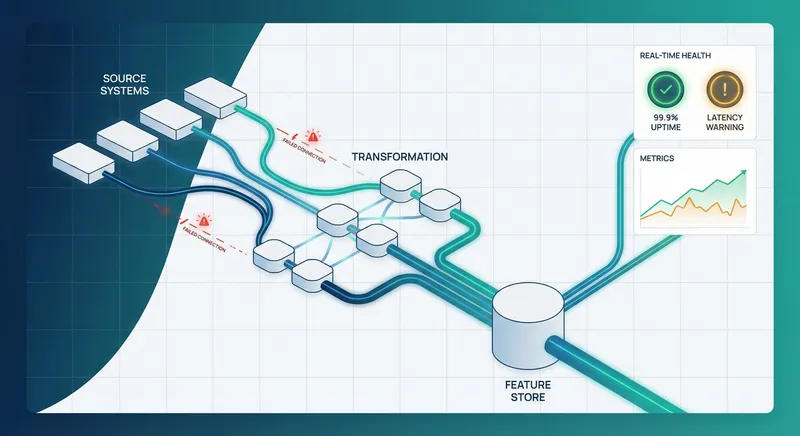
Feature Stores: The Central Hub for Predictive Scoring
A feature store is a specialized system that manages the full lifecycle of features - from definition and computation to storage and retrieval. For organizations running multiple predictive models, a feature store is transformational. It eliminates feature duplication across teams, ensures consistency between training and inference, and accelerates model development cycles. Learn more in our post on Balancing Autonomy and Compliance: Best Practices for Enterprise AI Governance.
Why Feature Stores Matter for Scoring Loops
Without a feature store, each data science team builds features independently. You end up with dozens of slightly different implementations of "customer lifetime value" or "engagement score" scattered across notebooks and scripts. This creates several problems:
- Training-serving skew: the features used during model training don't exactly match the features computed at inference time, causing performance degradation in production
- Slow iteration: building a new model requires weeks of feature engineering work rather than hours of model experimentation
- Governance gaps: no clear audit trail of which features feed which models, making it hard to trace data lineage or assess impact when a source system changes
- Redundant computation: the same raw data gets transformed dozens of times across different pipelines, wasting compute resources
A feature store addresses these challenges by centralizing feature management. Data engineers define features once, in a governed way, and make them available to all models through a consistent API.
Feature Store Architecture
Modern feature stores typically have three layers:
Batch layer: Periodically computes features from historical data and writes them to offline storage. Used for training datasets and for scoring when real-time freshness isn't critical. Batch features might be computed hourly, daily, or on a custom schedule depending on the use case.
Real-time layer: Computes features on demand or maintains a cache of recently computed features for immediate retrieval. Used for inference when you need fresh data - for example, scoring a lead immediately after they visit your website. The real-time layer typically includes a low-latency key-value store that can return features in milliseconds.
Serving layer: Provides a unified API for models and applications to request features. The serving layer abstracts away the complexity of knowing whether a feature comes from batch or real-time storage. It handles feature versioning, so models can request features by version number and always get the same definition they were trained on.
A well-designed feature store maintains point-in-time correctness. This means that when you request features for a historical record, you get the values that were actually available at that point in time, not the current values. This is critical for model training - it prevents data leakage and ensures your training data reflects realistic conditions.
Implementing Feature Governance
As your feature store grows, governance becomes essential. Implement a feature registry that documents every feature: its definition, owner, update frequency, dependencies, and which models use it. Require data owners to document their features in the registry before they can be used in production models.
Implement feature versioning. When a feature definition changes, increment the version number rather than overwriting the old definition. This lets existing models continue using the old version while new models can opt into the new version. Version changes should trigger automated retraining of affected models.
Track feature lineage - the upstream data sources and transformations that feed each feature. When a source system changes or a transformation logic is updated, you can automatically identify which features and models are affected. This visibility is crucial for managing impact and coordinating changes across teams.
A feature store eliminates the training-serving skew that undermines predictive model performance in production. By centralizing feature definitions and versioning, you ensure consistency between how models are trained and how they're deployed.
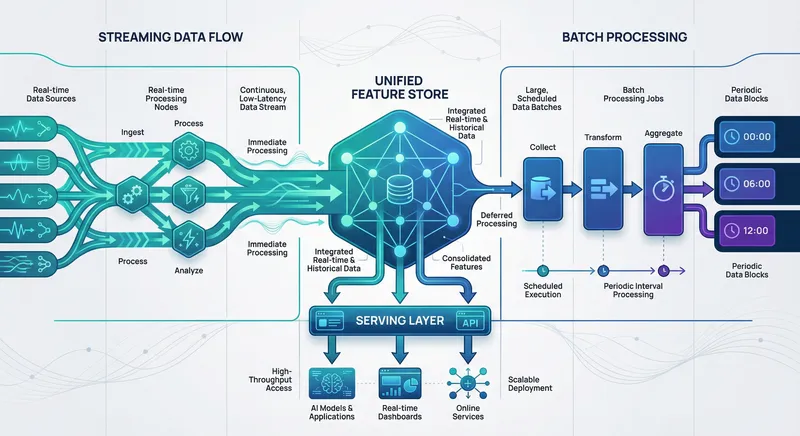
Streaming Versus Batch: Trade-offs and Best Practices
One of the most consequential decisions in designing a data orchestration system is choosing between streaming and batch processing - or more realistically, how to combine both approaches optimally.
Understanding the Trade-offs
Batch processing collects data over a period of time and processes it all at once. A batch job might run hourly or daily, reading all accumulated records, transforming them, and writing results to storage. Batch is efficient - you can process massive volumes with lower per-record costs. But it introduces latency. Data processed in a daily batch job isn't available for scoring until the next run.
Streaming processing handles data continuously, one record or small microbatch at a time. As soon as a record arrives, it's transformed and made available. Streaming enables near-real-time scoring and responses. But it's more complex operationally - you need to manage stateful computations, handle out-of-order arrivals, and deal with exactly-once semantics to avoid double-counting.
The right approach depends on your business requirements:
- If you're scoring leads for sales routing, you might need streaming to respond within seconds of a website visit
- If you're identifying at-risk customers for outbound campaigns, batch processing might be sufficient - scoring once daily is acceptable
- If you're detecting fraud in real-time transactions, you need streaming with sub-second latency
Most mature data orchestration systems use a hybrid approach: streaming for real-time features and immediate scoring needs, batch for stable features and periodic recomputation. This combines the best of both worlds.
Implementing a Hybrid Streaming-Batch Architecture
Start by identifying which features truly need real-time freshness and which can tolerate staleness. A feature like "customer's current session activity" needs streaming. A feature like "customer's industry" can be batch-computed daily.
For streaming features, use a streaming platform like Kafka or Pulsar to ingest events from operational systems. Implement stream processors that perform lightweight transformations - filtering, parsing, simple aggregations. Store results in a fast key-value store like Redis that can serve them at inference time with minimal latency.
For batch features, continue using your existing batch infrastructure (Spark, dbt, or similar). Run batch jobs on a regular schedule to compute features from historical data and write them to a data warehouse or data lake. The batch layer serves two purposes: it provides features for offline model training, and it provides fallback data when real-time sources are unavailable.
In your serving layer, implement logic to prefer real-time features when available but gracefully fall back to batch features if the real-time system is down. This ensures your scoring system is resilient to failures in either layer.
Be intentional about state management in streaming systems. If your features require aggregations (e.g., "customer's total purchases in the last 30 days"), you need to maintain state - the running aggregate value. Design your state management carefully: use a distributed state store that can be backed up and recovered, implement checkpointing so you can resume from where you left off if the processor crashes, and monitor state size to ensure it doesn't grow unbounded.
Handling Latency Requirements
Different scoring use cases have different latency requirements. Identify the latency SLA for each use case and design your architecture to meet it.
For scoring that must complete in under 100 milliseconds, you need features pre-computed and cached in a very fast store. You likely can't afford to query a data warehouse at inference time. Instead, load features into memory or a local cache and update them periodically from batch jobs.
For scoring that can tolerate 1-5 second latency, you have more flexibility. You might compute some features on demand during the scoring request, querying a data warehouse or calling an API to fetch enrichment data. This trades latency for flexibility - you can compute more complex features without pre-computing everything.
Document your latency SLAs explicitly and design your pipelines to meet them. Monitor actual latencies in production and alert when they degrade. Use this data to inform infrastructure investments - if you consistently miss latency targets, you may need to move features to a faster store or simplify computations.
Data Lineage and Governance for Predictive Scoring
As your data orchestration system grows, tracking lineage - the path that data takes from source to model - becomes increasingly important. Lineage enables you to answer critical questions: If a source system changes, which models are affected? If a prediction goes wrong, which data inputs contributed to that outcome? If a regulatory audit requires us to explain a decision, what data did we use?
Why Lineage Matters
Impact analysis: When a source system changes its schema or data quality degrades, lineage tells you immediately which downstream features and models are affected. This lets you prioritize fixes and coordinate changes across teams.
Explainability: For regulated industries like finance and healthcare, you need to explain why a model made a particular decision. Lineage documentation shows which data inputs fed the model, allowing you to trace decisions back to their sources.
Debugging: When a model's performance suddenly degrades, lineage helps you isolate the cause. Did a source system change? Did a transformation logic break? Did a feature computation start returning nulls? Lineage narrows the investigation scope.
Compliance: Data governance and privacy regulations require organizations to track data flows and implement controls. Lineage documentation proves that you've implemented appropriate safeguards and can demonstrate compliance to auditors.
Implementing Lineage Tracking
Start with automated lineage capture. Rather than relying on teams to manually document lineage, build it into your data orchestration platform. When data moves through a pipeline step, record the source and destination. When a transformation is applied, record the logic. This creates a continuous, accurate lineage graph.
Most modern data orchestration tools support automatic lineage capture. If you're building custom pipelines, implement metadata logging that records:
- Source system and table name
- Timestamp when data was read
- Transformation logic applied (as code or as a reference to a versioned script)
- Destination system and table name
- Data quality checks performed and results
- Owner and team responsible for the pipeline
Store this metadata in a centralized catalog that can be queried and visualized. Build dashboards that show lineage graphs - visual representations of how data flows through your system. These dashboards help non-technical stakeholders understand data dependencies and impact.
Establishing Data Quality Contracts
A data contract is an explicit agreement between a data producer and a data consumer about the quality and format of data. For example, a contract might specify: "The customer events table will be updated daily by 6 AM UTC, will contain at least 95% of events from the previous day, and will have no null values in the customer_id column."
Contracts make expectations explicit and enable automated enforcement. When a producer fails to meet a contract, downstream consumers are immediately notified and can take action - pausing scoring, using cached data, or alerting engineers.
Implement contract enforcement in your orchestration system. Before allowing data to flow downstream, validate it against the contract. If validation fails, trigger alerts and optionally block consumption. This prevents bad data from propagating through your system and affecting model predictions.
Contracts should be maintained collaboratively. Data producers should define what they can reliably deliver; data consumers should specify what they need to function correctly. When requirements change, update contracts and re-validate all downstream systems.
Audit Trails for Compliance
Maintain detailed audit trails of all changes to data, features, and models. Record who made changes, when they were made, what changed, and why. For predictive scoring systems used in regulated contexts, audit trails are non-negotiable.
Implement version control for all data pipelines and feature definitions. Use tools like Git to track changes to code. Require code reviews before changes are deployed to production. This creates a clear audit trail and prevents accidental errors from reaching production.
For data itself, implement immutability where possible. Rather than overwriting historical data, append new records and mark old ones as superseded. This preserves the historical record and makes it possible to reconstruct what data looked like at any point in time.
Data lineage and governance aren't just compliance checkboxes - they're strategic capabilities that enable faster debugging, safer changes, and greater confidence in automated decisions. Organizations that invest in lineage infrastructure move faster because they can change things with confidence.
Operationalizing Predictive Scoring Loops
A closed-loop predictive system is one where model outputs feed back into the system to improve future predictions. For example, a lead scoring model makes a prediction, a sales agent acts on that prediction, and the outcome (whether the lead converted) is captured and used to retrain the model. These feedback loops are where AI systems create compounding value - but they only work if your data orchestration can handle the complexity.
Designing Feedback Loops
The first challenge is capturing outcomes accurately. If your model predicts that a lead has a 70% conversion probability, you need to track whether that lead actually converted. This sounds simple but is often surprisingly difficult in practice.
Map the customer journey carefully. Identify all the touchpoints where a predicted outcome can be validated. A lead might convert through multiple channels - a phone call, an email, a website form. You need to capture all of these and consolidate them into a single "outcome" record that can be matched back to the original prediction.
Implement prediction logging. Every time your model makes a prediction, log the prediction ID, timestamp, input features, model version, and the predicted score. Store these logs in a queryable system. Later, when outcomes are known, you can join prediction logs with outcome data to create training examples for model retraining.
Be careful about feedback delays. Some outcomes are known immediately (did the customer click the email?). Others take weeks or months (did the customer churn?). Design your retraining pipeline to handle both fast and slow feedback loops. Fast feedback enables rapid iteration; slow feedback captures longer-term outcomes that might be more valuable for the business.
Continuous Model Retraining
As new outcome data arrives, retrain your model to incorporate it. But retraining isn't as simple as running the same training script with new data. You need to be thoughtful about several things:
Training data selection: Which historical outcomes should you use for training? A common approach is to use the most recent N months of data, which balances having enough training examples with capturing recent patterns. But if your business environment changes seasonally, you might want to include data from the same season in previous years.
Model validation: Before deploying a retrained model, validate that it actually performs better than the current model. Use a holdout test set that the model hasn't seen during training. Compare metrics like AUC, precision, and recall. If the new model doesn't improve, don't deploy it - investigate why the retraining didn't help.
Gradual rollout: When you do deploy a new model, don't immediately switch all traffic to it. Instead, route a small percentage of scoring requests to the new model while most traffic continues using the old model. Monitor the new model's performance in production. If it performs well, gradually increase traffic to it. If performance degrades, quickly roll back.
Monitoring for drift: Over time, the data distribution that your model sees in production might shift - a phenomenon called data drift. Your model was trained on historical data with a certain distribution, but production data has a different distribution. This causes model performance to degrade. Implement monitoring that detects data drift and triggers retraining when necessary.
Managing Prediction Freshness
Scoring loops raise a question: how fresh do predictions need to be? If you score a customer daily, you're using predictions that are up to 24 hours old. If you score every hour, predictions are fresher but you're computing more. There's a trade-off between freshness and computational cost.
Be explicit about freshness requirements for each use case. A fraud detection model might need predictions that are minutes old. A churn prediction model might be fine with daily predictions. Design your scoring schedule to match requirements, not to score everything as frequently as possible.
Implement on-demand scoring for cases where you need fresh predictions immediately. When a customer takes an important action (visits your website, opens an email), trigger a scoring request right then rather than waiting for the next scheduled batch. This adds latency but ensures you're making decisions with the freshest available data.
Implementing Data Quality as a Core Capability
Data quality is the foundation of reliable predictive scoring. Bad data leads to bad predictions, and bad predictions erode trust in your AI systems. Yet many organizations treat data quality as an afterthought - something to be addressed when problems occur rather than proactively prevented.
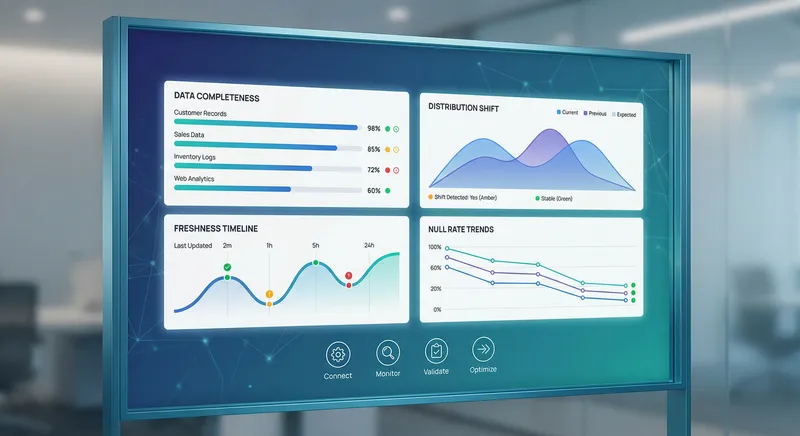
Defining Data Quality Dimensions
Data quality isn't a single metric - it's multidimensional. The key dimensions are:
Accuracy: Does the data correctly represent reality? A customer's age should match their birth date. A transaction amount should match what the customer actually paid. Accuracy is hard to measure without a ground truth source, but you can implement spot checks and reconciliations.
Completeness: Are all expected values present? Missing values can break feature computations or cause models to behave unexpectedly. Monitor the percentage of records with null values in each column and alert when it exceeds thresholds.
Consistency: Is data consistent across systems? If a customer's address is stored in both your CRM and your billing system, they should match. Implement reconciliation checks that compare values across systems and flag discrepancies.
Timeliness: Is data available when it's needed? A feature that's updated daily might be stale by the time it's used for scoring. Monitor the lag between when data is generated and when it's available for use.
Validity: Does data conform to expected formats and ranges? Customer ages should be positive integers between 0 and 150. Email addresses should match email format patterns. Implement schema validation that rejects data that doesn't conform to expectations.
Building Data Quality Checks
Implement automated checks that validate data quality throughout your pipeline. These checks should run continuously, not just once during initial development.
Create checks at multiple levels:
- Source system checks: validate data as it leaves the source system
- Transformation checks: validate data after each transformation step
- Feature checks: validate computed features before they're stored
- Consumption checks: validate that features consumed by models meet quality thresholds
For each check, define what "good" looks like. For example: "The email column should have no nulls, should match email format patterns, and the number of unique values should be between 10K and 10M." When data violates these expectations, the check fails and alerts are triggered.
Implement anomaly detection for data quality. Rather than defining hard thresholds, use statistical methods to detect when data behaves unexpectedly. If the distribution of a feature changes significantly, that's a signal that something might be wrong upstream.
Creating a Data Quality Culture
Technology alone isn't enough. You need to create a culture where data quality is everyone's responsibility. Data producers should care about the quality of data they generate. Data consumers should understand what quality they need and communicate that to producers. Leadership should prioritize data quality investments.
Implement data quality scorecards that track quality metrics over time. Share these scorecards with teams. Celebrate improvements and investigate degradations. Make data quality visible and important.
Invest in tools and training that help teams understand and improve data quality. Provide self-service dashboards where teams can see how their data is being used and what quality issues are affecting downstream systems. This feedback loop motivates quality improvements.
Scaling Data Orchestration as Your System Grows
Starting with a single predictive model is manageable. But as you deploy more models, add more data sources, and increase scoring frequency, complexity grows exponentially. A data orchestration system that works for one model might collapse under the weight of ten models.
Modular Pipeline Design
Design pipelines as composable modules rather than monolithic scripts. Each module should have a single responsibility - read from a source system, perform a specific transformation, or write to a destination. Modules should be independent, with clear inputs and outputs.
This modularity enables reuse. If multiple models need the same feature, you define it once as a module and reference it from multiple places. When the feature needs to change, you update it in one place and all models automatically use the new version.
Implement a dependency management system that tracks which modules depend on which other modules. When a module is updated, automatically identify and retest all downstream modules. This prevents changes from breaking things unexpectedly.
Infrastructure for Scale
As data volumes grow, your infrastructure needs to scale. Batch processing jobs that took 30 minutes with 1GB of data might take hours with 100GB. Streaming systems that handled 1,000 events per second might struggle with 100,000 events per second.
Use cloud infrastructure that can scale elastically. Run batch jobs on platforms like Spark or Flink that can distribute computation across many machines. Use managed services like cloud data warehouses that automatically scale capacity based on demand. This lets you focus on business logic rather than infrastructure management.
Implement resource quotas and cost monitoring. As your system scales, cloud costs can grow quickly. Set quotas that prevent runaway spending. Monitor costs per model and per feature. Use this data to identify expensive operations that might be optimized.
Team Structure and Responsibilities
As your data orchestration system grows, you need clear ownership and governance. Establish roles and responsibilities:
- Data engineers own the orchestration platform, pipelines, and infrastructure
- Data scientists own models and feature definitions
- Data stewards own data quality and governance
- Data owners (from business teams) are responsible for their source systems and data quality
Establish processes for collaboration. When a data scientist wants to create a new feature, they work with data engineers to implement it in the feature store. When a source system changes, the data owner notifies data stewards who assess impact and communicate with affected teams.
Create self-service tools that let teams operate independently within guardrails. A data scientist should be able to define a new feature and have it automatically added to the feature store without waiting for an engineer. But the feature should be validated against quality standards and reviewed by a data steward before being used in production.
Common Pitfalls and How to Avoid Them
Organizations implementing data orchestration for predictive scoring often encounter similar challenges. Learning from these common pitfalls can save you months of troubleshooting.
Training-Serving Skew
This is perhaps the most common pitfall. During model training, a data scientist computes features one way in a notebook. At inference time, a different piece of code computes features slightly differently. The model was trained on features with one distribution but receives features with a different distribution at inference time. Performance degrades mysteriously.
Prevent this by using a feature store that provides the same feature definitions for both training and inference. Version features so models can request features by version and always get the same definition they were trained on.
Slow Feedback Loops
You deploy a model but outcome data takes weeks to arrive. You can't retrain the model with fresh data. You can't quickly iterate on model improvements. The system stagnates.
Design your feedback loops to capture outcomes as quickly as possible. Even if you can't capture the ultimate business outcome (did the customer stay loyal?), capture intermediate signals (did they open the email? Did they click the link?). These fast signals let you iterate quickly while you wait for slow signals to arrive.
Feature Explosion
Without governance, the feature store grows to thousands of features. Most of them are unused or redundant. The feature catalog becomes unmaintainable. New data scientists can't find features they need.
Implement governance that requires features to be documented and actively maintained. Periodically audit the feature store and deprecate unused features. Establish naming conventions and organization schemes that make it easy to discover features. Make it easier to reuse existing features than to create new ones.
Ignoring Data Lineage
When something breaks, you have no idea what caused it. A source system changed and you don't know which models are affected. A feature computation broke and you don't know what downstream systems depend on it. You spend days debugging what should have been obvious.
Invest in lineage tracking from day one. It's much easier to build lineage into your system from the start than to retrofit it later. Use this lineage to proactively manage changes and prevent problems.
From Data Chaos to Predictive Excellence
Data orchestration is no longer a technical detail in AI systems - it's a core strategic capability that separates organizations that successfully deploy predictive scoring from those that struggle. When you orchestrate data well, you enable your models to learn continuously, adapt to changing conditions, and generate compounding value. When you neglect orchestration, even sophisticated models fail to deliver.
The best practices outlined in this guide - building resilient pipelines, implementing feature stores, managing streaming and batch processing, establishing lineage and governance, operationalizing feedback loops, and scaling thoughtfully - work together to create a foundation for reliable, explainable, and continuously improving predictive scoring systems.
The journey from fragmented data silos to a governed, orchestrated system doesn't happen overnight. It requires investment in tools, processes, and team capabilities. But the payoff is substantial: faster model development, higher prediction accuracy, better compliance, and the ability to automate decisions with confidence.
At A.I. PRIME, we help founder-led teams and small B2B operators implement data orchestration strategies that power their predictive scoring and autonomous AI workflows. We understand the engineering challenges, the governance requirements, and the organizational dynamics that make orchestration successful. Our team works with you to design pipelines that scale, implement feature stores that accelerate model development, and establish governance frameworks that give stakeholders confidence in your AI systems.
Whether you're building your first predictive scoring loop or scaling an existing system, we can help you navigate the technical and organizational complexity. We'll work with your teams to assess your current state, identify gaps, and implement best practices that drive measurable results. The goal isn't just to build a data orchestration system - it's to build a capability that compounds over time, enabling you to deploy more models, iterate faster, and extract more value from your data.
Ready to transform your data into a competitive advantage? Contact our team to discuss how data orchestration can power your predictive scoring and autonomous AI initiatives. Let's build the foundation for predictive excellence.
Conclusion
Data orchestration best practices are the invisible backbone of effective predictive scoring loops. Without them, even the most sophisticated machine learning models struggle to deliver consistent, reliable results. By implementing resilient pipelines, feature stores, comprehensive feedback mechanisms, and strong governance frameworks, you create an environment where predictive systems don't just work - they continuously improve.
The practices we've covered throughout this guide - from establishing data lineage to operationalizing feedback loops - aren't isolated technical decisions. They're interconnected elements of a holistic approach to data orchestration. Each practice reinforces the others, creating a system that's greater than the sum of its parts. When you get orchestration right, you unlock exponential improvements in model accuracy, development velocity, and organizational trust in AI-driven decisions.
The transition from manual, ad-hoc data processes to a fully orchestrated system requires commitment, but the returns justify the investment. Organizations that prioritize data orchestration today will find themselves significantly ahead of competitors tomorrow - with faster deployment cycles, higher prediction accuracy, and the confidence to scale AI across their operations.
Your path to predictive excellence starts with acknowledging that orchestration matters. It continues with strategic investment in the right tools and practices. And it compounds through disciplined execution and continuous refinement. The time to begin is now.
Next step
Book the Opportunity Sprint


