A.I. PRIME - Article
Integration Patterns: APIs, Event Streaming, and Connectors for Autonomous Agents
Master reliable autonomous systems integration with APIs, event streaming, and connector patterns for enterprise-scale agent networks.

Enterprise organizations deploying autonomous agents face a critical challenge: how do you reliably connect intelligent agents to legacy systems, cloud platforms, and real-time data streams without creating brittle, maintenance-heavy integrations? As your organization scales from pilot deployments to network-wide autonomous systems integration, the architecture decisions you make today will determine whether you achieve seamless orchestration or costly technical debt. This guide explores the integration patterns, architectural approaches, and connector design principles that enable autonomous systems integration at enterprise scale - ensuring your agent networks operate reliably across heterogeneous infrastructure while maintaining governance, observability, and performance.
Understanding the Integration Challenge for Autonomous Agent Networks
Autonomous agents don't operate in isolation. They need to interact with databases, call third-party APIs, trigger workflows, consume real-time events, and respond to changing business conditions. Unlike traditional point-to-point integrations, agent networks create multiplicative complexity: each agent may need to communicate with dozens of systems, and each system may serve multiple agents. Without a deliberate integration architecture, you risk creating a tangled web of dependencies that becomes impossible to govern, debug, or scale. Learn more in our post on Unified Command Center: Centralized Control for Distributed Agent Networks.
The core problem is that autonomous systems integration isn't just about moving data from point A to point B. It's about enabling agents to:
- Access real-time information with minimal latency
- Execute actions reliably with proper error handling and retries
- Maintain transactional consistency across distributed systems
- Adapt to changing data schemas and API contracts
- Operate within compliance and security boundaries
- Provide observability into agent decision-making and actions
Traditional integration approaches - whether point-to-point APIs or batch ETL processes - weren't designed for the dynamic, bidirectional communication patterns that autonomous agents require. REST APIs introduce latency and coupling. Batch processes create stale data. Message queues alone don't provide the request-response semantics agents need. The solution requires a thoughtful combination of multiple integration patterns, each suited to specific use cases within your agent network.
The most successful autonomous systems integration strategies don't choose a single pattern - they orchestrate multiple patterns in concert, selecting the right tool for each agent-to-system interaction based on latency requirements, consistency needs, and operational constraints.
REST and gRPC: Synchronous Integration Patterns for Agent-System Communication
Synchronous request-response patterns remain foundational for autonomous systems integration, but the choice between REST and gRPC carries significant implications for agent performance and developer experience. Learn more in our post on Best Practices: Designing Safe Reward Functions and Constraints for Autonomous Agents.
REST APIs: Ubiquity and Trade-offs
REST APIs dominate enterprise integration landscapes because they're simple, stateless, and work across every platform and firewall configuration. For autonomous agents, REST offers several advantages: broad ecosystem support, human-readable request-response cycles, and mature tooling for authentication and monitoring. Most enterprise systems expose REST endpoints, making them the default choice for connecting agents to existing infrastructure.
However, REST introduces latency and coupling that can constrain agent responsiveness. Each request requires HTTP overhead - DNS resolution, TCP connection establishment, TLS handshake for HTTPS. For agents making thousands of decisions per second across multiple systems, this overhead accumulates. REST also encourages tightly coupled integrations: if a downstream system is slow or unavailable, the agent blocks waiting for a response. This synchronous coupling makes it difficult to scale agent networks horizontally and increases vulnerability to cascading failures.
When designing REST integrations for autonomous agents, adopt these patterns to mitigate these constraints:
- Connection pooling: Reuse HTTP connections across multiple agent requests rather than establishing new connections for each call
- Circuit breakers: Fail fast when downstream systems are degraded, allowing agents to make alternative decisions rather than blocking indefinitely
- Request timeouts: Set aggressive timeouts (milliseconds to single seconds) to prevent agents from waiting for slow responses
- Caching: Cache frequently accessed data in agent memory or distributed caches to reduce API calls
- Bulk operations: Design REST endpoints that accept batch requests, reducing the number of round trips agents must make
REST authentication adds another layer of complexity for agent networks. OAuth2, API keys, and mutual TLS all require careful credential management. Consider implementing a centralized credential service that agents query for short-lived tokens, rather than embedding long-lived credentials in agent configurations.
gRPC: High-Performance Synchronous Communication
gRPC addresses many REST limitations through a fundamentally different approach. Built on HTTP/2, gRPC enables multiplexing - multiple concurrent requests over a single connection. It uses binary Protocol Buffers instead of JSON, reducing payload size and serialization overhead. For autonomous systems integration involving high-frequency agent-to-system communication, gRPC can reduce latency by 10x or more compared to REST.
gRPC is particularly valuable when agents need to make rapid decisions based on real-time data. A trading agent querying market data, a logistics agent optimizing routes, or a fraud detection agent evaluating transactions - these use cases benefit significantly from gRPC's low-latency characteristics. gRPC also provides strong typing through Protocol Buffers, enabling agents to validate requests and responses at the schema level before execution.
The trade-off is operational complexity. gRPC requires HTTP/2 support throughout your infrastructure, which can be challenging in legacy environments. It's less human-readable than REST, making debugging more difficult. And the ecosystem is smaller - not all enterprise systems expose gRPC endpoints natively.
For autonomous systems integration, consider a hybrid approach: use gRPC for high-frequency, latency-sensitive communication between agents and critical systems (databases, real-time data services), and REST for broader ecosystem connectivity and administrative operations.
The choice between REST and gRPC isn't binary. Leading organizations implement both: REST for broad connectivity and operational simplicity, gRPC for performance-critical agent-system interactions where latency matters.
Event Streaming: Asynchronous Integration for Real-Time Agent Networks
While synchronous APIs enable agents to request information on demand, event streaming inverts the model: systems publish events describing state changes, and agents subscribe to streams relevant to their decision-making. This asynchronous pattern is essential for autonomous systems integration because it decouples agents from the systems they monitor, enabling agents to operate independently without blocking on external system availability. Learn more in our post on The Rise of Real-Time Prescriptive Insights: Changing How Enterprises Operate.
Event Streaming Fundamentals
Event streaming platforms like Apache Kafka, AWS Kinesis, or cloud-native message services provide durable, ordered event logs that agents consume at their own pace. When a customer places an order, a sales system publishes an "OrderCreated" event. Multiple agents - a fulfillment agent, a billing agent, a notification agent - subscribe to this stream independently. Each agent processes the event according to its logic, without waiting for other agents or blocking the originating system.
This architecture provides several advantages for autonomous systems integration:
- Decoupling: Agents operate independently; system failures don't cascade
- Scalability: New agents can subscribe to event streams without modifying existing systems
- Replay capability: Agents can reprocess historical events to recover from failures or update logic
- Temporal ordering: Events maintain order within partitions, enabling agents to reason about causality
- Audit trail: Event streams provide immutable records of all state changes for compliance and debugging
For autonomous systems integration, design event schemas carefully. Events should describe what happened (the fact), not how other systems should react (the imperative). An "OrderCreated" event is better than an "InvoiceThisOrder" event - the latter prescribes behavior, while the former lets agents decide how to respond. Use versioning and schema registries to evolve event formats without breaking agent subscribers.
Implementing Event-Driven Agent Architectures
Event streaming enables powerful patterns for autonomous systems integration. Consider a supply chain optimization agent that needs to respond to inventory changes, demand signals, and shipping delays. Rather than polling multiple systems for updates, the agent subscribes to event streams from inventory management, demand forecasting, and logistics systems. When new events arrive, the agent updates its internal model and makes decisions in real time.
Implement event-driven agents with these patterns:
- Consumer groups: Organize agents into logical groups that share consumption state, enabling horizontal scaling and fault tolerance
- Idempotent processing: Design agent logic to handle duplicate events gracefully, since distributed systems may deliver events multiple times
- Event sourcing: Store agent decisions and state changes as immutable events, enabling perfect audit trails and state reconstruction
- Exactly-once semantics: Combine transactional outbox patterns with event streaming to ensure agent actions and event consumption remain consistent
- Dead letter queues: Route events that agents can't process to separate queues for manual investigation and recovery
Event streaming also enables sophisticated monitoring and governance for autonomous systems integration. By analyzing event streams, you can observe agent behavior, detect anomalies, and enforce business rules. A compliance agent can subscribe to all order events and flag suspicious patterns. A performance agent can track event processing latency and alert when agents fall behind.
Change Data Capture: Streaming Database Changes
Change Data Capture (CDC) extends event streaming to databases themselves. Rather than polling databases for changes or waiting for applications to publish events, CDC tools capture row-level changes directly from database transaction logs and stream them to event platforms. This is powerful for autonomous systems integration because it provides agents with real-time visibility into system state changes without requiring modifications to legacy applications.
CDC patterns work particularly well when agents need to monitor data in systems where you can't easily add event publishing. A legacy ERP system might not expose events, but CDC can capture invoice changes. A data warehouse might not publish update events, but CDC can stream dimension changes. For autonomous systems integration, CDC bridges the gap between modern event-driven architectures and legacy systems.
Implement CDC with careful attention to consistency. CDC tools must handle schema changes, ensure ordering guarantees, and manage transaction boundaries. For agents consuming CDC events, understand that database changes may represent intermediate states - an order might be created, then modified multiple times before reaching final state. Agent logic should be resilient to these intermediate updates.

Connector Architecture: Building Reliable Agent-System Bridges
While integration patterns describe how agents and systems communicate, connectors are the physical implementations - the code and configuration that enable specific integrations. Well-designed connectors are essential for autonomous systems integration at scale because they abstract complexity, provide consistent behavior, and enable rapid deployment of new agent capabilities.
Connector Design Principles
A connector is essentially an adapter that translates between an agent's abstract interface and a specific system's protocol, data format, and semantics. A Salesforce connector might expose methods like "create_lead," "update_opportunity," "query_accounts" that agents call, while internally handling Salesforce's REST API, field mappings, and authentication. A database connector might expose "query," "insert," "update" operations while managing connection pooling, transaction handling, and result formatting.
Design connectors with these principles:
- Abstraction: Hide system-specific details behind clean, agent-friendly interfaces
- Composability: Enable agents to combine connector operations into complex workflows
- Error handling: Provide rich, actionable error information that agents can use to make decisions
- Observability: Emit structured logs and metrics for every connector operation
- Resilience: Implement retries, timeouts, circuit breakers, and graceful degradation
- Security: Enforce authentication, authorization, and data encryption consistently
Consider a connector to a payment processing system. Rather than exposing the raw API (which might require agents to understand card tokenization, 3D Secure, webhook handling), the connector exposes a simple interface: "process_payment(amount, currency, customer_id)." Internally, the connector handles tokenization, fraud checks, retry logic, and webhook management. If the payment system is temporarily unavailable, the connector might queue the request and retry automatically, or return a "pending" status that agents understand.
Connector Patterns for Heterogeneous Systems
Enterprise environments include diverse systems - cloud applications, on-premise databases, legacy mainframes, IoT devices, third-party services. A robust connector strategy handles this diversity through layered abstractions.
Protocol adapters translate between different communication protocols. An agent might call a connector using gRPC, which internally translates to REST calls for a cloud API, SOAP calls for a legacy service, or direct database queries. The agent doesn't need to know or care about the underlying protocol - the connector handles it.
Data mappers transform between different data representations. A connector to a CRM system might accept agent requests using a normalized customer schema, then map those fields to the specific CRM's data model. When retrieving data, the connector maps CRM fields back to the normalized schema. This enables agents to work with consistent data models across diverse systems.
Semantic adapters bridge conceptual differences between systems. Different systems might represent the same business concept differently - one system calls it an "invoice," another calls it a "bill," another calls it a "transaction." Connectors translate between these semantic representations, enabling agents to reason about business concepts consistently.
Temporal adapters handle timing differences between systems. Some systems operate in real time, others batch hourly or daily. A connector might buffer agent requests and batch them for efficiency, or might cache system state and serve it locally with acceptable staleness. The connector shields agents from these timing complexities.
Building Connector Networks
As your autonomous systems integration scales, you'll build dozens or hundreds of connectors. Rather than building each from scratch, establish connector frameworks and libraries that provide common functionality.
A connector framework might provide:
- Base classes for authentication, error handling, and logging
- Retry and circuit breaker implementations
- Request/response validation and transformation
- Connection pooling and resource management
- Metrics collection and distributed tracing
- Configuration management and secret handling
Individual connectors then focus on system-specific logic - API calls, data mapping, business rule implementation - while inheriting robust infrastructure from the framework. This dramatically accelerates connector development and ensures consistent behavior across your agent network.
Version connectors explicitly and manage versions carefully. An agent might depend on version 2.3 of a Salesforce connector, while another depends on version 3.0. Your connector infrastructure should support multiple versions running simultaneously, enabling gradual migration as agents update their dependencies.
The most scalable autonomous systems integration strategies treat connectors as products, not one-off implementations. Invest in connector frameworks, documentation, and governance - the return on investment multiplies as your agent network grows.
Governance, Security, and Observability in Autonomous Systems Integration
Integration patterns and connectors are technical foundations, but autonomous systems integration at enterprise scale requires governance, security, and observability to ensure agents operate reliably within organizational boundaries and compliance requirements.
Integration Governance
As autonomous systems integration scales, agents gain access to critical business systems. Without governance, agents might make decisions that violate policies, access sensitive data inappropriately, or execute actions outside authorized boundaries. Implement governance through multiple layers:
Connector-level governance enforces rules at the integration point. A connector to the payroll system might enforce that agents can only query employee data for employees in their department. A connector to the financial system might enforce daily transaction limits. These rules are defined once in the connector and apply consistently to all agents using it.
Agent-level governance enforces rules specific to agent capabilities. A sales automation agent might be authorized to create leads and opportunities, but not delete them. A procurement agent might have spending limits based on approval hierarchies. Define these rules in agent policies and enforce them before connectors execute.
Workflow-level governance enforces rules about how agents can combine operations. An agent might be authorized to both query customer data and send emails, but a workflow combining these might be restricted to prevent spam. Implement workflow validation to detect and prevent unauthorized operation combinations.
Data-level governance enforces rules about what data agents can access. Implement field-level security so agents only see data they're authorized to access. Use role-based access control (RBAC) or attribute-based access control (ABAC) to define fine-grained permissions. Audit all data access for compliance.
Security for Agent-System Integration
Autonomous systems integration expands the attack surface: agents now have programmatic access to critical systems. Secure this expanded surface through multiple mechanisms:
Authentication: Agents must prove their identity before accessing systems. Implement mutual TLS for agent-to-system communication, or use short-lived OAuth2 tokens issued by a central identity service. Never embed long-lived credentials in agent code.
Authorization: Agents must have explicit permission for each operation. Implement fine-grained authorization checks at connector level - a connector should verify that the calling agent has permission for the requested operation before executing it.
Encryption: Encrypt data in transit (TLS) and at rest. When agents retrieve sensitive data, ensure it's encrypted in agent memory or cache. When agents transmit data, use encrypted channels.
Audit logging: Log every agent action, including what was requested, who made the request, what data was accessed, and what happened. Maintain immutable audit logs for compliance and forensics.
Rate limiting: Prevent agents from overwhelming systems through excessive requests. Implement rate limits at connector level - if an agent exceeds its quota, the connector queues requests or returns an error.
Observability for Autonomous Systems Integration
When agents interact with multiple systems, debugging failures becomes complex. An agent's decision might depend on data from five different systems; if the outcome is wrong, which system is responsible? Implement comprehensive observability:
Distributed tracing: Assign each agent action a unique trace ID. As the action flows through connectors and systems, include the trace ID in logs and metrics. This enables you to follow the complete path of an action across systems.
Structured logging: Log in structured format (JSON) that includes agent ID, action type, system called, request and response details, latency, and errors. This enables efficient searching and analysis.
Metrics: Collect metrics for every connector operation - request count, latency percentiles, error rates, and system-specific metrics. Use these metrics to detect degradation and capacity issues.
Alerts: Define alerts for anomalous behavior - agents making unusual numbers of requests, connectors returning errors, latency spikes, authorization failures. Alert on both system-level issues (API is down) and agent-level issues (agent is behaving unexpectedly).
Agent decision tracing: Log the data agents used to make decisions, the reasoning process, and the actions taken. This enables you to explain agent behavior to stakeholders and audit decisions for compliance.
Practical Implementation: Building Your Autonomous Systems Integration Architecture
Understanding integration patterns intellectually is one thing; implementing them reliably at scale is another. This section provides practical guidance for building autonomous systems integration architectures in real enterprises.
Assessment and Planning
Before building integrations, assess your current landscape. Document the systems agents need to access, the frequency of access, the data involved, and the latency requirements. Map out dependencies - does agent A's decision depend on data from system B, which depends on system C? Understanding these dependencies helps you choose appropriate integration patterns.
Evaluate your existing infrastructure. Do you have event streaming platforms? Message queues? API gateways? Existing infrastructure constrains your choices - you might prefer gRPC but lack HTTP/2 support, so REST becomes more practical. Do you have identity and access management systems? These should be central to your integration security strategy.
Identify quick wins - integrations that unlock significant agent capabilities with minimal effort. These build momentum and demonstrate value. Perhaps you have REST APIs already exposed for most systems, making REST a natural starting point. Or perhaps you have Kafka already deployed, making event streaming immediately available.
Incremental Implementation Strategy
Don't try to build perfect autonomous systems integration from the start. Instead, implement incrementally:
- Start with REST APIs for breadth - connect agents to as many systems as possible using REST, even if it's not optimal for all use cases
- Identify performance bottlenecks - measure agent latency and identify which integrations are slowest
- Optimize critical paths - convert high-frequency, latency-sensitive integrations to gRPC or event streaming
- Build connector frameworks - once you have multiple connectors, extract common patterns into reusable frameworks
- Implement governance - once agents are operating reliably, layer on governance, security, and observability
- Scale the network - with solid foundations, scale agent networks across more use cases and systems
This incremental approach reduces risk and builds organizational capability over time. You learn what works in your specific environment rather than trying to implement a perfect architecture that might not fit your constraints.
Connector Development Workflow
Establish a repeatable workflow for developing new connectors. When a business need arises for agents to interact with a new system, follow this process:
- Requirements gathering: Document what operations agents need (create, read, update, delete, query), what data is involved, and latency requirements
- System analysis: Understand the target system's API, authentication, data models, rate limits, and error handling
- Connector design: Design the agent-facing interface - what methods will agents call, what parameters do they take, what results do they return
- Implementation: Implement the connector using your connector framework, handling authentication, error handling, retries, and logging
- Testing: Test against both happy path (normal operations) and error cases (system down, rate limited, invalid data)
- Security review: Verify authentication, authorization, encryption, and audit logging
- Performance testing: Measure latency under load and verify it meets requirements
- Documentation: Document the connector's interface, limitations, authentication requirements, and examples
- Deployment: Deploy the connector to your agent infrastructure with versioning and gradual rollout
- Monitoring: Monitor connector health and performance in production, alert on degradation
This workflow ensures connectors are reliable, secure, and well-documented. It also creates organizational knowledge about integration patterns and best practices.
Handling Integration Failures
In distributed systems, failures are inevitable. Networks timeout, systems crash, data is inconsistent. Design autonomous systems integration to handle these failures gracefully:
Transient failures: When a connector call fails temporarily (network timeout, temporary service unavailability), retry with exponential backoff. Most transient failures resolve within seconds.
Permanent failures: When a connector call fails permanently (authentication error, invalid data, system refusing the operation), fail fast and let the agent handle the error. The agent might try an alternative approach, queue the action for manual review, or escalate to a human.
Partial failures: When an agent has executed some actions successfully but others failed, maintain consistency. Use compensating transactions - if an agent creates an order but fails to reserve inventory, cancel the order. Or use saga patterns - coordinate multi-step operations across systems with rollback capabilities.
Data consistency: When integrating with multiple systems, data might be temporarily inconsistent - a customer was created in the CRM but not yet in the billing system. Design agents to tolerate eventual consistency. Use connector idempotency to ensure operations can be retried safely.
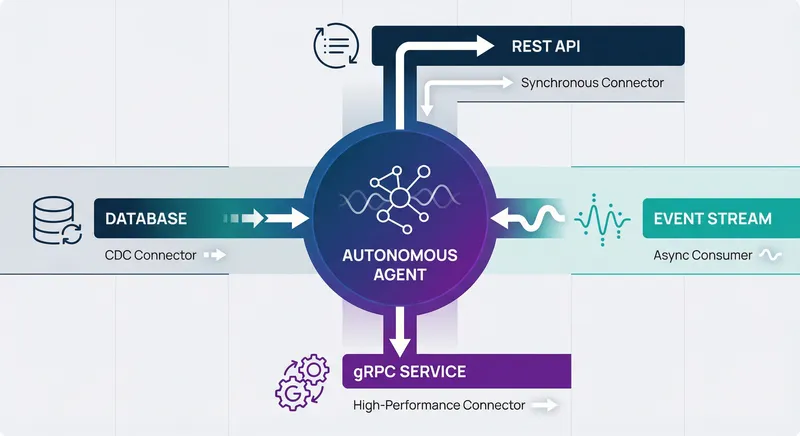
Advanced Integration Patterns for Complex Autonomous Systems
Beyond basic REST, gRPC, and event streaming, several advanced patterns enable sophisticated autonomous systems integration for complex enterprise scenarios.
Saga Pattern for Distributed Transactions
When agents need to coordinate operations across multiple systems while maintaining consistency, sagas provide a powerful pattern. A saga is a sequence of local transactions coordinated across systems. If any transaction fails, compensating transactions undo previous changes, maintaining consistency without distributed locks or two-phase commit (which don't scale in distributed systems).
Consider an order fulfillment saga: create order, reserve inventory, process payment, schedule shipment. If payment fails, the saga compensates by canceling the order and releasing inventory. Each step is a local transaction in a specific system; the saga orchestrates these transactions and handles failures.
Implement sagas with connectors that expose both forward operations and compensating operations. A connector to the inventory system exposes "reserve_inventory" and "release_inventory." The saga orchestrator calls these in sequence, using compensating operations when failures occur.
Eventual Consistency Patterns
Autonomous systems integration often requires accepting eventual consistency - data might be temporarily inconsistent across systems, but will become consistent over time. This is more scalable than strict consistency, which requires synchronous coordination.
Design agents to tolerate eventual consistency. An agent might retrieve a customer's balance from the billing system, which might be slightly stale (updated a few seconds ago). The agent makes a decision based on this stale data, and the decision is correct with high probability. If the balance changes slightly, the impact is usually acceptable.
Use event streaming to propagate state changes asynchronously. When a customer's balance changes, an event is published. Agents and systems that need the updated balance subscribe to this event and update their local state. This is more scalable than synchronous REST calls that require immediate consistency.
Bulkhead Pattern for Fault Isolation
In agent networks, one slow or failing system can degrade the entire network if not isolated. The bulkhead pattern isolates failures by dividing resources into separate compartments. If one compartment fails, others continue operating.
Implement bulkheads at connector level. Each connector gets its own thread pool, connection pool, and circuit breaker. If a connector to a slow system exhausts its resources, other connectors continue operating normally. Agents waiting for the slow connector timeout and move on, rather than blocking the entire agent network.
Measuring Success: Metrics for Autonomous Systems Integration
How do you know if your autonomous systems integration architecture is working? Define metrics that measure reliability, performance, and business impact:
- Connector availability: Percentage of time each connector is operational and responding within SLA. Target 99.5% or higher for critical connectors.
- Agent decision latency: Time from when an agent needs information to when it receives it and makes a decision. Lower latency enables faster agent response to business events.
- Integration reliability: Percentage of agent actions that succeed on first attempt without errors or retries. Target 99%+ for critical operations.
- Error recovery time: Time to recover from integration failures - how quickly do agents resume normal operation when systems fail. Target minutes or less.
- Data freshness: Age of data agents use for decisions. For real-time systems, target seconds or less. For batch systems, target hours or less.
- Governance compliance: Percentage of agent actions that comply with governance policies. Target 100% - any violation indicates a governance failure.
- Business impact: Revenue generated, costs saved, or efficiency gains from autonomous systems integration. This is the ultimate measure of success.
Track these metrics continuously and use them to guide optimization priorities. If connector availability is 95% but business impact is high, invest in reliability improvements. If latency is high but availability is good, optimize for performance.
Conclusion: Building Enterprise-Grade Autonomous Systems Integration
Autonomous systems integration is the connective tissue that enables agent networks to operate reliably across enterprise infrastructure. The integration patterns you choose - REST, gRPC, event streaming, CDC - fundamentally shape how agents access information, execute actions, and respond to business events. The connectors you build encapsulate system-specific complexity and enable agents to operate at a higher level of abstraction. The governance, security, and observability you implement ensure agents operate within organizational boundaries and enable you to understand and audit agent behavior.
At A.I. PRIME, we specialize in designing and implementing autonomous systems integration architectures that enable enterprises to deploy agent networks at scale. Our approach combines deep technical expertise in integration patterns with practical understanding of enterprise constraints, legacy systems, and governance requirements. Whether you're building your first autonomous agent or scaling a network of hundreds of agents, we help you choose the right integration patterns, design robust connectors, and implement governance that enables your agents to operate reliably and compliantly.
The journey from pilot deployments to network-wide autonomous systems integration requires careful architectural decisions and ongoing optimization. It's not a one-time project, but an evolving practice of building capabilities, learning from experience, and continuously improving. We work with your teams throughout this journey, helping you establish connector frameworks, implement governance policies, build observability infrastructure, and scale agent networks as your organization's needs evolve.
If you're planning autonomous systems integration projects, facing integration challenges with existing agent deployments, or building connector networks at scale, we'd like to help. Our autonomous systems integration services include architecture assessment, connector development, governance implementation, and continuous optimization. We combine proven integration patterns with your organizational context to build solutions that drive real business value. Let's discuss how autonomous systems integration can accelerate your digital transformation and unlock new capabilities in your agent networks. Reach out to explore how A.I. PRIME can support your autonomous systems integration initiatives.
Next step
Book the Opportunity Sprint