A.I. PRIME - Article
Agent Network Deployment: Scaling Multi-Agent Orchestration for the Enterprise
agent network deployment: Master enterprise automation by scaling multi-agent orchestration with proven deployment architecture and governance strategies.

Enterprise operations today face a critical inflection point. Legacy workflows remain siloed and inefficient, while competitive pressure demands faster decision-making and seamless automation across distributed teams. Yet most organizations struggle with a fundamental challenge: how do you deploy autonomous agents at scale without losing control, visibility, or operational stability?
The answer lies in architecting a robust agent network deployment strategy - one that treats multiple AI agents not as isolated tools, but as an interconnected ecosystem. This approach enables organizations to orchestrate complex workflows across departments, geographies, and systems while maintaining governance, observability, and the agility to adapt as business needs evolve. Whether you're automating sales processes, optimizing supply chains, or accelerating customer service, the principles of agent network deployment unlock the ability to multiply your operational capacity without proportionally increasing headcount or risk.
This guide walks you through the practical architecture, deployment patterns, and scaling strategies that allow enterprises to harness autonomous agents as a coordinated force. We'll explore how to design networks that grow with your business, maintain security and compliance at every layer, and deliver measurable ROI from day one.
Understanding Agent Network Deployment Architecture
Agent network deployment is fundamentally different from deploying a single automation tool. Rather than replacing one manual process with one bot, you're building an interconnected system where multiple agents work in concert, each handling specialized tasks while remaining aware of and responsive to one another's actions and outputs. Learn more in our post on Blueprinting Autonomous Workflows: From Process Mapping to Deployment.
At its core, an agent network consists of three architectural layers. The agent layer comprises the autonomous workers themselves - each agent designed with a specific domain expertise, whether that's processing invoices, qualifying leads, managing inventory, or handling customer escalations. The orchestration layer sits above these agents, routing work, managing dependencies, and ensuring that outputs from one agent become inputs for another in a coordinated sequence. The governance and observability layer wraps around everything, providing real-time visibility into agent performance, enforcing compliance rules, and enabling human oversight at critical decision points.
This layered approach matters because it decouples agent logic from orchestration logic. You can upgrade, replace, or add new agents without disrupting the broader network. An agent that handles customer sentiment analysis can be swapped out for a more advanced version without requiring changes to the workflow that routes its output to a response generation agent. This composability is what allows enterprises to scale from dozens to hundreds of agents while maintaining manageability.
The topology you choose - whether centralized, distributed, or hybrid - depends on your operational footprint and risk tolerance. A centralized topology routes all orchestration through a single cognitive engine, offering simplicity and unified control but creating a potential bottleneck. A distributed topology deploys orchestration logic closer to the point of work, reducing latency and improving resilience but introducing complexity in synchronization and governance. Most enterprises benefit from a hybrid approach: core orchestration remains centralized for policy enforcement and compliance, while edge orchestration handles local routing and real-time decisions.

Provisioning and Integration Strategies
Deploying an agent network into an existing enterprise environment requires careful planning around integration points, data access, and system dependencies. The goal is to enable agents to operate autonomously while respecting existing infrastructure investments and security boundaries. Learn more in our post on Integration Patterns: APIs, Event Streaming, and Connectors for Autonomous Agents.
Integration Patterns for Legacy Systems
Most enterprises operate with a patchwork of systems - ERP platforms, CRM databases, accounting software, document management systems - that were never designed to communicate with autonomous agents. Successful agent network deployment acknowledges this reality and builds integration layers that allow agents to interact with these systems safely and reliably.
API-first integration is the foundation. Each system that agents need to access should expose well-defined APIs with appropriate authentication, rate limiting, and audit trails. If legacy systems lack APIs, middleware solutions can bridge the gap by translating agent requests into system-specific commands. This approach isolates agents from system complexity while creating a consistent interface layer.
Event-driven architecture amplifies this pattern. Rather than agents continuously polling systems for changes, systems emit events when relevant actions occur - a new customer inquiry, an order status change, an invoice approval. Agents subscribe to these events and react in real time, dramatically reducing latency and system load compared to pull-based approaches.
Data Access and Security Boundaries
Agents need access to data to make decisions, but unrestricted access creates security and compliance risks. Implement a role-based access control layer that defines what data each agent can read and write. An agent handling customer support interactions might access customer records and order history but not financial data. An agent managing inventory might modify stock levels but not access employee records.
This control layer should be separate from the agent logic itself - defined in a central policy engine rather than hardcoded into individual agents. This allows you to update permissions globally without redeploying agents. It also creates an audit trail of exactly what data each agent accessed and when, critical for compliance audits.
Consider implementing data masking and tokenization for sensitive fields. An agent processing customer payment information doesn't need to see full credit card numbers - a tokenized reference is sufficient. This reduces the blast radius if an agent is compromised or behaves unexpectedly.
Successful agent network deployment treats data access as a first-class architectural concern, not an afterthought. The agents that can do their job with the least data exposure are the safest agents.
Orchestration Topology and Load Management
As your agent network grows from dozens to hundreds or thousands of agents, the orchestration layer becomes the critical nerve center. How you design this layer determines whether your network scales smoothly or buckles under load. Learn more in our post on Change Management for Automation: Engaging Stakeholders and Building AI Fluency.
Choosing Your Orchestration Model
Workflow orchestration can follow several patterns, each with tradeoffs. In a linear orchestration model, work flows through agents in a defined sequence - agent A processes input, passes output to agent B, which passes to agent C, and so on. This is simple to understand and debug but inflexible when work needs to branch based on conditions or when agents need to work in parallel.
Directed acyclic graph (DAG) orchestration allows more complex patterns. Work can branch into parallel paths, reconverge, and take different routes based on conditions. An incoming customer inquiry might simultaneously trigger a sentiment analysis agent and a classification agent, with their outputs feeding into a response generation agent. DAG orchestration is more powerful but requires more sophisticated runtime management.
Event-driven orchestration decouples agents entirely. Rather than a central orchestrator telling agents what to do, agents listen for events they care about and react autonomously. When one agent completes work, it emits an event. Other agents subscribed to that event type wake up and process it. This pattern scales extremely well and is inherently resilient - if one agent is slow or unavailable, it doesn't block others - but requires careful design to avoid cascading failures or infinite loops.
Most enterprise deployments start with DAG orchestration for clarity and control, then evolve toward event-driven patterns as they mature and need greater scale. The key is ensuring your orchestration platform can support this evolution without requiring wholesale replacement.
Load Balancing and Resource Allocation
Agents are software processes that consume compute resources. As your network grows, you need mechanisms to ensure work is distributed fairly and that no single agent becomes a bottleneck or monopolizes resources.
Dynamic load balancing distributes incoming work across multiple instances of the same agent type. If you have five instances of a document processing agent, incoming documents are routed to the least-loaded instance. This prevents any single instance from becoming overwhelmed and enables horizontal scaling - add more instances as demand grows.
Queue-based load management decouples work submission from work execution. Instead of agents being called synchronously, work is submitted to queues. Agents pull from queues at their own pace, processing work in order. This provides natural backpressure - if agents can't keep up, work queues grow, signaling that you need more agent capacity. It also enables priority queuing, where urgent work is processed before routine work.
Resource limits prevent runaway agents from consuming all available compute. Set CPU and memory limits for each agent type. If an agent exceeds limits, it's throttled or restarted. This is a safety mechanism - a buggy agent or one facing unexpected data volumes won't crash the entire network.
Implement monitoring and alerting on queue depths and agent latency. If queues are consistently long or agents are slow, that's a signal to increase capacity. Automated scaling can handle this - when queue depth exceeds a threshold, automatically spawn additional agent instances. When demand drops, scale down to save costs.
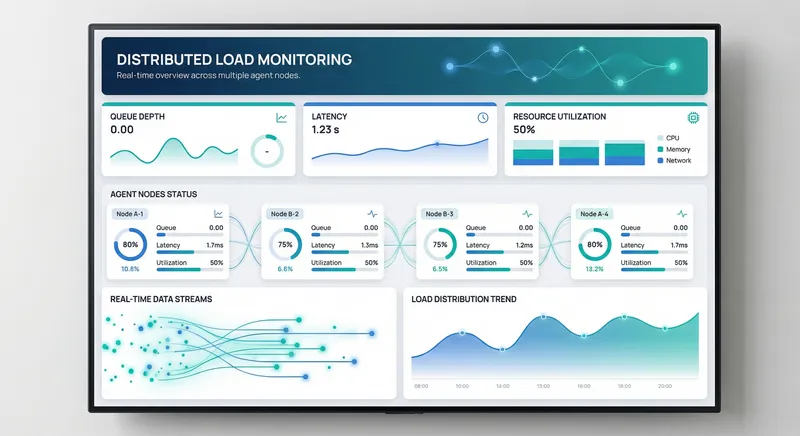
Observability and Monitoring for Agent Networks
You cannot manage what you cannot see. Observability - the ability to understand system behavior from external outputs - is non-negotiable for agent networks at scale. Without it, you're flying blind, unable to diagnose failures or optimize performance.
Instrumentation and Logging
Every agent action should be logged with sufficient context to reconstruct what happened. At minimum, capture the timestamp, agent ID, input data, output data, execution time, and any errors. But go deeper - log the reasoning steps an agent took, the data it accessed, the decisions it made. This transforms logs from a debugging tool into a source of business intelligence.
Structure logs consistently using a standard format like JSON. This allows log aggregation tools to parse and search them efficiently. Include unique trace IDs that follow work through the entire network - from initial input through multiple agents to final output. This allows you to answer questions like "what happened to customer order 12345 as it moved through our network?"
Implement log levels thoughtfully. Debug logs capture granular details useful during development and troubleshooting. Info logs record significant events - agent startup, work completion, errors. Warning logs flag anomalies - an agent taking unusually long, an unexpected data format. Error logs capture failures. This hierarchy allows you to adjust verbosity based on environment and investigation needs.
Metrics and Performance Monitoring
Logs tell you what happened; metrics tell you how well things are working. Key metrics for agent networks include throughput (work items processed per unit time), latency (time from input to output), error rate (percentage of work that fails), and resource utilization (CPU, memory, network consumed).
Instrument agents to emit these metrics continuously. Use time-series databases designed for metrics - they're optimized for high-volume writes and efficient querying of trends over time. Visualize metrics in dashboards that show real-time status and historical trends. A dashboard might show that a particular agent type's latency has been creeping up over the past week - a signal to investigate before it becomes a problem.
Set up alerts on metric thresholds. If error rate exceeds 5%, alert on-call staff. If latency doubles from baseline, trigger an investigation. These alerts should be tuned to minimize false positives - constant alerts breed alert fatigue and cause teams to ignore them.
Implement SLO (Service Level Objective) tracking. Define what "good" looks like - perhaps 99% of work completes within 5 seconds with less than 1% error rate. Track your actual performance against these objectives. When you miss SLOs, conduct postmortems to understand why and prevent recurrence. When you consistently exceed SLOs, you have room to add more work without degrading quality.
Distributed Tracing
In a network with many agents, work often flows through multiple agents before completion. Distributed tracing allows you to follow a single work item through the entire journey, seeing how much time each agent spent on it, where delays occurred, and how different agents contributed to the final result.
Implement tracing by assigning a unique trace ID to each work item when it enters the network. Every agent that touches that work item includes the trace ID in its logs and metrics. Tracing tools then reconstruct the timeline - showing that work item A spent 200ms in agent X, 500ms in agent Y, 150ms in agent Z. This pinpoints bottlenecks and reveals optimization opportunities.
Observability isn't just about detecting problems after they occur. It's about understanding your system deeply enough to anticipate problems and optimize before issues impact customers.
Governance and Compliance Integration
Autonomous agents make decisions and take actions on behalf of your organization. This creates regulatory and compliance obligations. Your agent network deployment must embed governance from the ground up, not bolt it on afterward.
Policy Enforcement and Guardrails
Governance policies define what agents are allowed to do. A sales agent might be allowed to offer discounts up to 15% but not higher. A customer service agent might be allowed to issue refunds up to $500 but must escalate larger amounts to humans. A procurement agent might be authorized to create purchase orders from approved vendors but not unauthorized suppliers.
Implement these policies in a centralized policy engine separate from agent logic. When an agent wants to take an action, it queries the policy engine - "am I allowed to offer this discount?" The policy engine evaluates the request against current policies and returns allow or deny. This approach enables rapid policy updates without redeploying agents. If you discover that your discount authority was too high, update the policy once and it applies to all agents immediately.
Build in escalation paths for edge cases. If an agent encounters a situation not covered by policy - perhaps a customer requesting a refund for a reason not anticipated - it escalates to a human rather than making a guess. Humans review these escalations, and if they're common, the policy gets updated to handle them automatically in the future.
Implement audit trails that capture every decision agents make, especially decisions with financial or compliance implications. Who approved this decision? What data did the agent consider? What policy was applied? These audit trails are critical for regulatory compliance and for defending your organization if decisions are later questioned.
Compliance Monitoring and Reporting
Regulatory requirements vary by industry and jurisdiction. Healthcare organizations must comply with HIPAA. Financial institutions must comply with SOX and AML regulations. Retail organizations must comply with consumer protection laws. Your agent network must be designed to support these requirements.
Implement data retention policies that ensure personally identifiable information (PII) and other sensitive data is retained only as long as required, then securely deleted. Agents should be designed to minimize PII exposure - they should work with tokenized or anonymized data whenever possible.
Build reporting capabilities that generate compliance evidence. Can you produce a report showing that all customer data access was logged and authorized? That all financial transactions were reviewed against AML policies? That all decisions were made according to documented procedures? These reports are what regulators expect to see.
Conduct regular audits of agent behavior. Sample work items and manually review the decisions agents made. Did they follow policies correctly? Did they escalate appropriately? Did they log everything properly? Use audit findings to improve agent training or policies.
Deployment and Rollout Strategies
Deploying an agent network into production carries risk. A single misconfigured agent or unexpected interaction between agents could disrupt core operations. Successful deployments minimize this risk through careful rollout strategies.
Phased Rollout Approach
Start with a pilot program. Deploy your agent network to a limited set of users or use cases - perhaps a single department or a subset of customer interactions. Run the pilot in parallel with existing processes, not as a replacement. This allows you to compare agent performance against human performance, identify issues in a controlled environment, and build organizational confidence in the system.
Define success criteria for the pilot. What would success look like? Perhaps agents handle 80% of customer inquiries without human intervention, with 95% accuracy, and 90% customer satisfaction. Measure against these criteria. If you hit targets, expand. If you fall short, diagnose why and iterate.
Once the pilot succeeds, move to a phased rollout. Rather than deploying to the entire organization overnight, roll out to one region, department, or customer segment at a time. This allows you to detect and resolve region-specific or department-specific issues before they affect the whole organization. It also gives teams time to adapt to new workflows and processes.
Maintain fallback capabilities throughout rollout. If agents fail or behave unexpectedly, ensure you can quickly revert to human processes. This might mean keeping human staff trained and available to handle work if agents are unavailable. It might mean maintaining the ability to instantly disable agent decision-making and switch to human review mode.
Canary Deployments and A/B Testing
When deploying new agent versions or new agents to your network, use canary deployments. Route a small percentage of work - perhaps 5% - to the new version while the majority continues using the current version. Monitor the new version closely. If it performs well, gradually increase the percentage until it handles 100% of work. If it performs poorly, roll back immediately without affecting the majority of users.
Use A/B testing to compare agent approaches. Perhaps you have two different strategies for handling customer escalations. Route some escalations to strategy A and others to strategy B. Compare outcomes - which strategy results in faster resolution? Higher customer satisfaction? Lower cost? Use these insights to optimize agent behavior.
Implement feature flags that allow you to enable or disable agent capabilities without redeploying code. If you discover that an agent's new feature causes problems, disable it with a flag change rather than rolling back an entire deployment. This enables rapid iteration and risk reduction.
Monitoring and Incident Response
Even with careful planning, issues will occur. Prepare for them with robust monitoring and incident response procedures. Define what constitutes an incident - perhaps error rate exceeding 5%, latency exceeding SLOs, or a critical agent becoming unavailable. When incidents are detected, automatically alert on-call staff.
Establish incident response procedures. Who is responsible for responding? What are the first steps - assess impact, stabilize the system, investigate root cause, implement permanent fix? Conduct blameless postmortems after incidents - focus on what failed and how to prevent recurrence, not on blaming individuals.
Maintain runbooks for common issues. If a particular agent frequently becomes unresponsive, the runbook might say "restart the agent and check for memory leaks." If orchestration becomes slow, the runbook might say "check queue depths and scale up if needed." These runbooks allow faster incident response and reduce the expertise required to respond.
The goal of incident response isn't to prevent all incidents - that's impossible. The goal is to detect incidents quickly, respond effectively, and learn from them to prevent recurrence.
Scaling Strategies and Capacity Planning
As your agent network matures and takes on more work, you'll need to continuously expand capacity. Scaling isn't a one-time event but an ongoing process of monitoring demand, predicting future needs, and provisioning resources accordingly.
Horizontal and Vertical Scaling
Horizontal scaling means adding more agent instances. If your document processing agents are overwhelmed, deploy more instances and distribute work across them. Horizontal scaling is preferred because it's flexible - you can add or remove instances based on demand - and it improves resilience - if one instance fails, others continue working.
Vertical scaling means giving existing instances more resources - more CPU, more memory. This is simpler operationally but has limits - there's only so much CPU and memory you can add to a single machine. It also reduces resilience - a failure affects a larger portion of your work.
Most enterprise deployments use primarily horizontal scaling with occasional vertical scaling for agents that need more resources per instance. Use containerization and orchestration platforms like Kubernetes to manage this scaling automatically. Define resource requests and limits for each agent type, and let the platform handle provisioning and scheduling.
Capacity Planning and Forecasting
Monitor your current capacity utilization - how much of your agent network's total processing capacity are you currently using? If utilization is consistently above 80%, you're at risk of overload. If it's consistently below 50%, you're over-provisioned and wasting money.
Forecast future demand based on business plans. If the sales team is planning a major campaign, demand for lead qualification agents will increase. If you're entering a new market, demand for localization agents might spike. Use these forecasts to provision capacity in advance rather than scrambling when demand hits.
Implement auto-scaling policies that automatically adjust capacity based on demand. If queue depth exceeds a threshold, automatically add instances. If queue depth drops, automatically remove instances. This keeps you right-sized for current demand without manual intervention.
Track cost per work item processed. As you scale and optimize, this cost should decrease - you're handling more work with the same infrastructure. If cost per item increases, that signals inefficiency that needs investigation.
Continuous Optimization and Evolution
Agent network deployment isn't a project with an endpoint - it's an ongoing practice of improvement. The networks that deliver the most value are those that continuously evolve based on performance data and changing business needs.
Performance Tuning and Optimization
Use observability data to identify optimization opportunities. If a particular agent is consistently slow, investigate why. Is it waiting for external system responses? Is it processing large data volumes inefficiently? Once you understand the bottleneck, you can address it - perhaps by adding caching, parallelizing work, or optimizing algorithms.
Regularly review agent decision quality. Sample work items and evaluate whether agents made good decisions. If error rates are high in specific scenarios, retrain agents or adjust policies. If agents are escalating too much, perhaps they need more authority or better training.
Conduct regular cost reviews. Are you spending more on infrastructure than necessary? Are there agents that could be consolidated? Are there opportunities to reduce API calls or data transfers? Small optimizations compound over time.
Expanding Agent Capabilities
As your network matures, expand what it can do. Perhaps your initial network handles routine customer inquiries. Over time, add agents that handle complex issues, manage escalations, and coordinate with human teams. Perhaps your initial network automates simple processes. Over time, add agents that handle more complex, multi-step processes.
Invest in agent training and fine-tuning. Modern AI agents can be improved through additional training on your specific data and use cases. If agents are making mistakes, collect examples of those mistakes and use them to improve training. If agents are missing opportunities, expose them to examples of good decisions and let them learn from them.
Experiment with new agent types and capabilities. Allocate a portion of your team's time to exploring emerging capabilities - perhaps conversational agents that can handle nuanced customer interactions, or predictive agents that anticipate customer needs before they're expressed. Run these experiments in controlled environments, learn what works, and scale what succeeds.
Conclusion
Agent network deployment represents a fundamental shift in how enterprises approach automation. Rather than replacing individual manual tasks with individual automated tasks, you're building interconnected systems of autonomous agents that work in concert to multiply your operational capacity and accelerate decision-making.
The enterprises that succeed with agent networks are those that approach deployment systematically - architecting for scale and resilience from day one, building observability into every layer, embedding governance and compliance into the foundation, and treating deployment as an ongoing evolution rather than a one-time project.
The good news is that you don't have to figure this out alone. This is exactly where A.I. PRIME specializes. We work with mid to large enterprises to design and deploy agent networks tailored to their specific operations, industries, and compliance requirements. Whether you're automating sales processes, optimizing supply chains, accelerating customer service, or transforming operational workflows, we help you architect networks that deliver measurable ROI while maintaining the control and visibility your organization requires.
Our approach combines strategic consulting to understand your unique challenges, workflow design to optimize how agents coordinate, governance integration to ensure compliance and control, and continuous enablement support to help your teams adapt and thrive with new automation capabilities. We've helped organizations across technology, finance, healthcare, manufacturing, and other industries deploy agent networks that increase operational efficiency by 40-60%, reduce manual work by 70-80%, and deliver ROI within months rather than years.
If your organization is ready to move beyond point automation and build a scalable, governed, observable agent network that transforms how you operate, let's talk. We'll assess your current state, identify high-impact automation opportunities, and design a deployment strategy that minimizes disruption while maximizing value. Contact us today to schedule a consultation and discover how agent network deployment can accelerate your digital transformation.
Next step
Book the Opportunity Sprint