A.I. PRIME - Article
Real-Time Insight Loops: Prescriptive Analytics to Shorten Decision Cycles
Accelerate decision-making with real-time insight loops that compress cycles from weeks to minutes using prescriptive analytics.

Enterprise leaders face a persistent paradox: they have more data than ever, yet decisions still move at a snail's pace. Traditional analytics workflows rely on batch processing, manual interpretation, and delayed reporting cycles that leave decision-makers working with yesterday's information. When markets shift in hours and competitors iterate daily, this lag becomes a competitive liability. The question isn't whether you can collect data - it's whether you can act on insights fast enough to matter. Real-time insight loops bridge this gap by creating continuous feedback mechanisms that ingest telemetry, score opportunities, and push prescriptive actions directly to your operational teams. This architecture transforms analytics from a reporting function into an operational engine that drives immediate, informed decisions at scale.
Understanding Real-Time Insight Loops and Their Strategic Value
A real-time insight loop is a closed-loop system that continuously ingests data from operational sources, processes it through analytical models, and delivers actionable recommendations back to decision-makers or autonomous agents in near-real time. Unlike traditional batch analytics that run on fixed schedules, insight loops operate as living systems - constantly observing, learning, and responding to changing conditions. Learn more in our post on The Rise of Real-Time Prescriptive Insights: Changing How Enterprises Operate.
The strategic value lies in compression: compressing the time between observation and action. In sales, this means identifying high-probability opportunities within hours rather than weeks. In operations, it means detecting anomalies before they cascade into failures. In customer experience, it means personalizing interactions based on current behavior rather than historical profiles. For mid to large enterprises managing complex workflows across distributed teams, this compression translates directly to revenue protection, cost reduction, and competitive advantage.
Consider a practical scenario: a manufacturing facility experiences a subtle shift in equipment sensor readings. Traditional analytics might flag this anomaly in next week's report. By then, the equipment has degraded further, maintenance costs have doubled, and production has stalled. A real-time insight loop detects the anomaly within minutes, scores the risk, and automatically routes a prescriptive maintenance recommendation to the operations team with specific guidance on parts, timing, and priority. The facility avoids downtime entirely.
Real-time insight loops transform analytics from a historical reporting function into an operational engine that drives immediate, informed decisions at scale - compressing decision cycles from weeks to hours or minutes.
This architecture also enables what we call prescriptive autonomy - the ability for AI-driven agents to not just report findings but recommend and even execute actions within defined guardrails. Rather than waiting for humans to interpret dashboards and make decisions, the system proposes the optimal next step based on real-time context, risk assessment, and business rules. Human oversight remains, but the burden of analysis shifts from humans to machines, freeing your teams to focus on judgment calls and strategic decisions.
Architecting the Core Components of a Real-Time Insight Loop
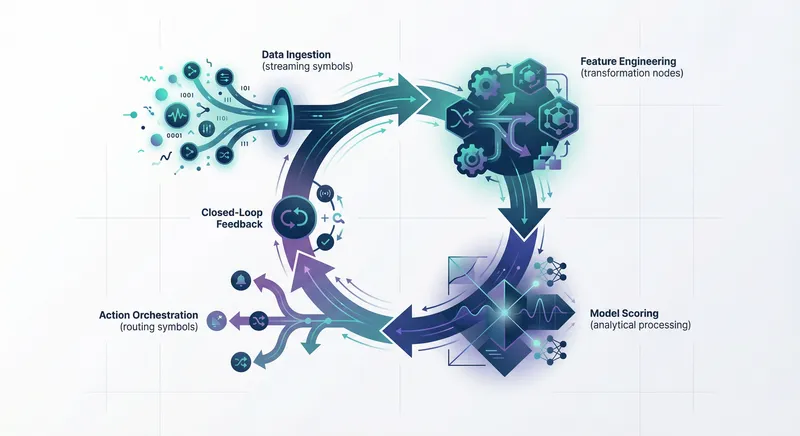
Building an effective real-time insight loop requires careful orchestration of five interconnected components: data ingestion, feature engineering, predictive or prescriptive models, action orchestration, and closed-loop evaluation. Each layer must be designed with both speed and reliability in mind. Learn more in our post on Continuous Optimization: Implement Closed‑Loop Feedback for Adaptive Workflows.
Data Ingestion and Telemetry Collection
The foundation of any real-time system is reliable, low-latency data ingestion. This means moving beyond periodic data exports or API polls to event-driven architectures where data flows continuously from source systems into your analytics infrastructure.
In practice, this involves deploying event streaming platforms (such as Kafka, Pulsar, or cloud-native equivalents) that capture operational telemetry in real time. Rather than waiting for a nightly batch job, every transaction, sensor reading, customer interaction, or system event flows into a central stream. This creates a continuous feed of raw material for analysis.
The key challenge is managing data volume and ensuring that critical signals don't get lost in noise. Not all data is equally valuable. A high-velocity sales organization might generate millions of call logs daily, but only a fraction contain signals relevant to deal progression. Your ingestion architecture must filter, prioritize, and route data intelligently. This typically involves lightweight preprocessing at the edge - close to the data source - to reduce noise and focus on high-signal events before they enter your analytics pipeline.
Another critical consideration is latency. Ingestion latency (the time between event generation and availability for analysis) should be measured in seconds, not minutes or hours. This often requires moving from cloud data warehouses designed for batch analytics to real-time streaming platforms designed for millisecond responsiveness. The investment in this infrastructure is substantial, but the operational value justifies it when decisions depend on current information.
Feature Engineering and Real-Time Enrichment
Raw telemetry is rarely actionable on its own. A single sensor reading tells you little; a pattern of readings over time tells you much more. Feature engineering - the process of transforming raw data into meaningful signals - is where raw telemetry becomes intelligence.
In a real-time context, feature engineering must happen continuously and incrementally. Rather than waiting to batch-process a week's worth of data, your system computes features as new data arrives. This might involve calculating rolling averages, detecting anomalies relative to baselines, scoring customer engagement based on recent activity, or measuring sales velocity based on pipeline changes in the last 24 hours.
Real-time feature engineering also enables contextual enrichment. As a new data point arrives, your system can instantly augment it with relevant context: historical patterns, market conditions, customer segment information, or competitive activity. This enrichment happens in memory, using cached reference data, so latency remains low.
A practical example: when a sales agent logs a customer interaction, your insight loop immediately enriches that event with the customer's account health score, recent engagement history, product affinity, and propensity to expand. Rather than the agent having to manually research this context, it's available instantly, enabling faster, more informed decisions about next steps.
Predictive and Prescriptive Modeling
Once features are engineered, they flow into analytical models that score opportunities, predict outcomes, or recommend actions. In real-time insight loops, these models must balance accuracy with speed - a model that takes 30 seconds to score an opportunity is too slow if you need to respond within seconds.
This typically means favoring simpler, faster models over complex ones. A gradient-boosted tree model that scores in 50 milliseconds is more valuable than a deep neural network that takes 2 seconds, even if the neural network is slightly more accurate. The speed advantage enables more frequent scoring and faster feedback loops.
Prescriptive models go beyond prediction. Rather than simply forecasting that a deal is at risk, they recommend specific actions: which customer should be contacted, when, through which channel, with which message. These models encode business logic, risk tolerance, and strategic priorities into their recommendations, ensuring that actions align with organizational goals.
The shift from predictive to prescriptive is significant. Predictive models answer "what will happen?" Prescriptive models answer "what should we do about it?" This shift requires integrating domain expertise into model design. Data scientists alone cannot build prescriptive models; they need input from operations leaders, sales managers, and compliance teams who understand the constraints and objectives that should shape recommendations.
Action Orchestration and Agent Networks
Insights are only valuable if they lead to action. This is where real-time insight loops connect to your operational infrastructure - your agent networks, workflow engines, and decision systems.
When your insight loop scores an opportunity as high-priority, it must trigger a corresponding action: routing to a specific sales agent, escalating to a manager, triggering an automated workflow, or adjusting resource allocation. This routing must be intelligent, considering agent availability, specialization, workload, and past performance with similar opportunities.
In modern architectures, this is handled by autonomous agent networks - distributed systems of AI-driven agents that receive recommendations from your insight loop and execute actions within defined guardrails. An agent might receive a recommendation to contact a specific customer with a specific offer, validate that the offer is compliant and appropriate given the customer's history, and then execute the outreach through the most effective channel.
This architecture decouples insights from execution, enabling your insight loop to operate at machine speed while human judgment remains available for edge cases or high-stakes decisions. The agent network becomes the operational expression of your insight loop's intelligence.
Closed-Loop Evaluation and Continuous Improvement
The final component - and the one that distinguishes true insight loops from one-way analytics pipelines - is closed-loop evaluation. Every action recommended by your insight loop should generate feedback that improves future recommendations.
When an agent acts on a recommendation, the outcome is captured: did the customer respond positively? Did the recommended action lead to the desired result? This feedback flows back into your models, enabling continuous learning. Over time, your prescriptive models become more accurate, more attuned to your specific business context, and more effective at driving desired outcomes.
This is where real-time insight loops diverge from static analytics. A traditional analytics model is trained once, deployed, and then left to degrade over time as business conditions change. A real-time insight loop continuously retrains and refines its models based on outcome data. This adaptive approach ensures that your recommendations remain relevant and effective even as markets, customer preferences, and competitive dynamics shift.
The evaluation component also serves a governance function. By tracking outcomes against recommendations, you create an audit trail that demonstrates model fairness, identifies potential biases, and ensures compliance with regulatory requirements. This is essential for enterprises operating in regulated industries or managing sensitive decisions.
Addressing Data Latency and Technical Challenges
Building real-time insight loops introduces technical challenges that batch-oriented organizations rarely encounter. Understanding and addressing these challenges is essential for reliable operationalization. Learn more in our post on Data Orchestration Best Practices to Power Predictive Scoring Loops.
Managing End-to-End Latency
Latency is the enemy of real-time systems. Every millisecond between observation and action is an opportunity lost. Yet achieving low latency across all components is technically demanding.
The latency budget - the total time available from data generation to action execution - must be allocated across all pipeline stages. If your business requirement is to recommend an action within 500 milliseconds, you might allocate: 100 ms for data ingestion and queuing, 150 ms for feature engineering, 100 ms for model inference, 100 ms for action orchestration, and 50 ms for routing to the agent network. Exceed any of these budgets, and your end-to-end latency suffers.
Achieving these targets requires architectural decisions that prioritize speed. This often means trading some batch-processing efficiency for streaming efficiency. A data warehouse optimized for 100-million-row queries might not be suitable for sub-second feature lookups. You may need to invest in in-memory data stores, specialized streaming databases, or edge computing infrastructure positioned close to data sources.
Another latency challenge is model inference at scale. If you're scoring thousands of opportunities per second, your models must be fast enough to handle this throughput without becoming a bottleneck. This drives choices toward simpler models, model optimization techniques (like quantization or pruning), and distributed inference infrastructure that parallelizes scoring across multiple machines.
Ensuring Data Quality and Freshness
Real-time systems are only as good as the data flowing through them. Data quality issues that are minor in batch systems become critical in real-time systems because they compound rapidly. A data quality issue that affects 1 percent of a weekly batch is a nuisance; the same issue affecting 1 percent of a real-time stream affects thousands of decisions daily.
This requires implementing continuous data quality monitoring. Rather than validating data quality once during ingestion, you need ongoing validation that checks for anomalies, drift, and inconsistencies as data flows through the pipeline. When data quality issues are detected, your system should alert operators and gracefully degrade - perhaps falling back to more conservative recommendations or routing decisions to humans for manual review.
Data freshness is equally critical. In some cases, slightly stale data is worse than no data - a customer segment definition that's 24 hours out of date might lead to incorrect routing decisions. Real-time insight loops must manage data freshness explicitly, understanding which data sources can tolerate slight delays and which require near-perfect timeliness.
This often involves maintaining multiple versions of data: a fresh version used for time-sensitive decisions and a slightly older, more complete version used for batch analytics. The complexity of managing this dual-version approach is significant but necessary for systems that must be both fast and accurate.
Handling Scale and Throughput
As your insight loops mature and prove their value, usage grows. What started as a system processing thousands of events per second may need to handle millions. This scaling challenge affects every component of your architecture.
Streaming platforms must be horizontally scalable, capable of distributing data ingestion and processing across multiple nodes. Feature stores must handle high-throughput lookups without becoming a bottleneck. Model inference infrastructure must scale elastically, spinning up additional capacity during peak periods. The entire system must remain responsive and accurate even under heavy load.
Scaling also introduces complexity around ordering and consistency. In distributed systems, guaranteeing that events are processed in order and that state remains consistent becomes harder as you add nodes. Some insight loop applications can tolerate eventual consistency (where different parts of the system briefly see different views of the world), but others require strict ordering and consistency. Understanding your tolerance for these trade-offs guides architectural decisions.
Real-time systems demand continuous data quality monitoring, explicit freshness management, and elastic scaling infrastructure - investments that pay dividends through faster decisions and better outcomes at scale.
Model Governance and Reliability in Production
As insight loops push prescriptive recommendations directly into operations, governance becomes critical. Unlike exploratory analytics where errors are learning opportunities, production insight loops make decisions that affect customers, revenue, and risk. Failures are costly.
Establishing Model Governance Frameworks
Model governance addresses the full lifecycle of analytical models: development, validation, deployment, monitoring, and retirement. In real-time insight loops, this governance must be continuous and automated rather than episodic and manual.
Start with clear model ownership. Every model in your insight loop should have a designated owner - typically a data scientist or analytics engineer - responsible for its performance, fairness, and compliance. This ownership includes understanding the model's assumptions, limitations, and known failure modes.
Next, establish validation standards. Before a model is deployed to production, it should be validated against rigorous criteria: accuracy on holdout test sets, performance across different customer segments or market conditions, fairness metrics that ensure the model doesn't discriminate against protected groups, and adversarial testing that attempts to find edge cases where the model fails.
Documentation is essential. Every model should have clear documentation of its purpose, inputs, outputs, performance characteristics, and known limitations. This documentation serves multiple purposes: it helps new team members understand the model, it provides evidence of due diligence for compliance audits, and it guides decisions about when to retire or replace the model.
Monitoring Model Performance in Production
Models degrade over time. Market conditions change, customer behavior shifts, and competitors introduce new offerings. A model trained on last year's data may perform poorly on this year's data. Real-time insight loops must detect this degradation and alert operators before it impacts business outcomes.
This requires continuous monitoring of model performance metrics. Track not just overall accuracy but performance across important segments: by customer type, geography, product category, or other dimensions relevant to your business. If accuracy drops significantly for a particular segment, investigate why and decide whether to retrain, adjust the model, or disable recommendations for that segment.
Also monitor for data drift - changes in the statistical properties of input data that might affect model performance. If your model was trained on data where 30 percent of customers were in the technology sector, but that proportion has shifted to 50 percent, the model's behavior may change. Detecting these shifts early allows you to proactively retrain before performance degrades.
Establish clear thresholds for action. Define what level of performance degradation triggers a manual review, what triggers retraining, and what triggers immediate rollback to a previous model version. These thresholds should be set in collaboration with business stakeholders who understand the cost of errors in your specific context.
Implementing Guardrails and Risk Controls
Even well-performing models can make mistakes in edge cases or under unusual conditions. Real-time insight loops must include guardrails - automated checks that prevent or flag problematic recommendations before they reach operators.
Common guardrails include: maximum action thresholds (don't recommend actions for more than X percent of customers in a day, as this likely indicates a model failure), consistency checks (flag recommendations that contradict recent actions for the same customer), business rule validation (ensure recommendations comply with pricing policies, compliance rules, and risk limits), and anomaly detection (flag recommendations that are unusual relative to historical patterns).
These guardrails operate as a second line of defense, catching model errors before they impact operations. When a guardrail is triggered, the system should not silently suppress the recommendation; instead, it should flag it for human review, allowing operators to investigate and decide whether to proceed or override the model's recommendation.
Implement a circuit breaker pattern: if error rates exceed a threshold, automatically disable the insight loop for that decision type and route all decisions to human review. This prevents a failing model from cascading errors across your entire operation. Once the issue is resolved, you can gradually re-enable the model, perhaps starting with a subset of lower-risk decisions.
Operationalizing Real-Time Insight Loops: From Pilot to Scale
Moving from prototype to production requires thoughtful operationalization. Many organizations build impressive proof-of-concepts that never scale to enterprise reliability. The difference lies in operational discipline and investment in supporting infrastructure.
Starting with Focused Use Cases
Resist the temptation to build a single insight loop that handles all decisions. Instead, start with a focused, high-value use case where the business impact is clear and measurable. This might be identifying high-probability sales opportunities, detecting equipment failures before they occur, or personalizing customer communications based on real-time behavior.
A focused use case offers several advantages. It limits the scope of data integration and model development, reducing complexity and time-to-value. It creates a clear success metric that business stakeholders can understand and measure. And it generates early wins that build confidence and justify further investment.
As your first insight loop matures, you can expand to related use cases. A sales opportunity loop can be extended to include account expansion opportunities or churn risk detection. An equipment monitoring loop can be extended to predictive maintenance across additional equipment types. This incremental expansion allows you to reuse infrastructure and learnings from the first loop while managing risk.
Building Data Integration and Orchestration
Real-time insight loops depend on seamless data flow from operational systems. This requires robust data integration infrastructure that connects your CRM, ERP, sales engagement platforms, customer data platforms, and other operational systems to your analytics infrastructure.
Modern data orchestration platforms enable this integration with minimal custom coding. Rather than building point-to-point connectors between systems, you can use a central orchestration layer that manages data flow, transformation, and routing. This approach scales better as you add new systems and new insight loops.
Establish clear data ownership and stewardship. Which team owns the customer data that feeds into your insight loops? Who is responsible for data quality? Who has authority to change data definitions or structures? Without clear ownership, data integration becomes a source of friction and conflict.
Also plan for data governance and compliance. If your insight loops process personally identifiable information or other sensitive data, ensure that your data integration infrastructure meets privacy and security requirements. Implement data masking, access controls, and audit logging as needed.
Establishing Operations and Support Processes
Real-time insight loops require ongoing operational support. Someone needs to monitor system health, respond to alerts, investigate anomalies, and coordinate with stakeholders when issues arise.
Establish an on-call rotation for your insight loop infrastructure. Define clear escalation paths: when a model's performance degrades, who investigates? When data quality issues arise, who is responsible for remediation? When an insight loop makes a costly error, who leads the post-mortem and implements preventive measures?
Create runbooks that document common operational scenarios: how to investigate high error rates, how to roll back a model version, how to disable an insight loop in an emergency, how to manually override recommendations. These runbooks should be accessible to your operations team and regularly tested to ensure they remain accurate.
Invest in observability - the ability to understand what your insight loops are doing and why. Implement comprehensive logging that captures inputs, model outputs, guardrail checks, and final actions. Build dashboards that surface key operational metrics: latency, throughput, error rates, and business outcomes. When something goes wrong, rich observability data enables rapid diagnosis and resolution.
Measuring Business Impact and ROI
Ultimately, insight loops must deliver measurable business value. Define clear success metrics before deployment and track them rigorously.
For a sales opportunity insight loop, success metrics might include: increase in pipeline coverage, improvement in win rates for recommended opportunities, reduction in time-to-close, or increase in deal size. For an operations insight loop, metrics might include: reduction in unplanned downtime, improvement in equipment efficiency, or reduction in maintenance costs. For a customer experience loop, metrics might include: improvement in customer satisfaction scores, increase in retention, or increase in customer lifetime value.
Establish baselines before deployment. What was performance before the insight loop? This baseline enables you to quantify the impact of your investment. Track metrics continuously, comparing performance before and after deployment, and accounting for other factors that might influence results.
Communicate results to stakeholders regularly. Business leaders need to see that their investment in real-time insight loops is generating returns. If results are strong, this builds momentum for expanding to additional use cases. If results are disappointing, this triggers investigation into root causes and course correction.
Integrating Insight Loops with Autonomous Agent Networks
Real-time insight loops reach their full potential when integrated with autonomous agent networks - distributed systems of AI-driven agents that can execute actions based on recommendations with minimal human intervention.
An autonomous agent receives a recommendation from your insight loop, validates it against business rules and compliance requirements, and then executes the recommended action. For example, a sales agent might receive a recommendation to contact a specific customer with a specific offer. The agent validates that the offer is appropriate given the customer's history and current status, checks that outreach is compliant with communication preferences, and then executes the outreach through the most effective channel - email, phone, or in-app message.
This architecture enables what we call prescriptive autonomy: the ability for AI systems to not just recommend actions but execute them within defined guardrails. This dramatically accelerates decision cycles. Rather than waiting for humans to interpret recommendations and manually execute actions, agents execute recommendations in real time, freeing human teams to focus on judgment calls and strategic decisions.
Integrating insight loops with agent networks requires careful design of the handoff between systems. The insight loop must provide agents with sufficient context to execute actions intelligently: not just "contact this customer" but "contact this customer with this offer, at this time, through this channel." The agent must have access to real-time customer data to validate recommendations and adjust execution as needed. And the agent must feed outcome data back to the insight loop to enable continuous learning.
This creates a virtuous cycle: better insights lead to better agent actions, which generate better outcome data, which improves future insights. Over time, your insight loops and agent networks learn to work together more effectively, compressing decision cycles and improving outcomes.
Best Practices for Real-Time Insight Loop Implementation
Based on successful deployments across diverse industries, several best practices emerge for real-time insight loop implementation:
- Start with business outcomes, not technology. Define the business problem you're solving and the metric you'll use to measure success before designing technical architecture. This ensures your insight loop is solving a real problem and that success is measurable.
- Invest in data quality from day one. Poor data quality will undermine even the best models. Establish data quality standards, implement continuous monitoring, and create processes for rapid remediation of issues.
- Favor simplicity over sophistication. A simple model that's fast, understandable, and reliable is more valuable than a complex model that's slow and opaque. Start simple and add complexity only if needed to achieve business outcomes.
- Build governance into the architecture. Don't treat governance as an afterthought. Implement monitoring, guardrails, and decision audit trails from the beginning.
- Establish clear ownership and accountability. Assign specific individuals responsibility for different components of your insight loop. This ensures issues are addressed promptly and prevents the diffusion of responsibility.
- Plan for continuous improvement. Your insight loops should improve over time as you gather outcome data and refine models. Build processes for regular model retraining and performance evaluation.
- Communicate results to stakeholders. Business leaders need to see that your insight loops are generating value. Share metrics regularly and celebrate successes to build momentum for expansion.
Future Directions: Adaptive and Self-Optimizing Insight Loops
Real-time insight loops continue to evolve. Emerging capabilities promise even greater impact:
Adaptive learning: Rather than retraining models on a fixed schedule, adaptive models continuously learn from new data and outcome feedback. This enables insight loops to respond to market changes and business evolution in real time.
Multi-objective optimization: Most current insight loops optimize for a single objective (maximize revenue, minimize cost, improve customer satisfaction). Future loops will balance multiple objectives simultaneously, navigating trade-offs intelligently.
Causal inference: Current models are largely correlational - they identify patterns in historical data. Causal models will enable insight loops to understand not just what leads to outcomes, but why, enabling more robust recommendations even when market conditions change.
Federated learning: As privacy regulations tighten, federated learning approaches will enable organizations to build insight loops that learn from data without centralizing sensitive information. Models will be trained collaboratively across distributed data sources.
These advances will make real-time insight loops even more powerful, but the fundamentals remain constant: continuous observation, rapid analysis, intelligent action, and closed-loop learning. Organizations that master these fundamentals today will be positioned to adopt advanced capabilities tomorrow.
Conclusion: Transforming Decision Velocity into Competitive Advantage
Real-time insight loops represent a fundamental shift in how enterprises approach decision-making. Rather than relying on periodic reports and delayed analysis, organizations can now observe operational reality continuously, analyze it in real time, and act with precision and speed. This transformation has profound implications for competitive advantage.
For enterprises seeking to operationalize these capabilities, the journey requires investment across multiple dimensions: technology infrastructure to ingest and process data at scale, analytical talent to build and maintain models, operational discipline to ensure reliability and governance, and organizational change to embrace AI-driven decision-making. The investment is substantial, but the returns are equally substantial for organizations that execute well.
At A.I. PRIME, we partner with mid to large enterprises to architect and deploy real-time insight loops tailored to your specific business context. Our approach combines deep expertise in autonomous agents, data orchestration, and governance to deliver insight loops that are fast, reliable, and continuously improving. We help you navigate the technical challenges of real-time systems, establish governance frameworks that ensure safe autonomy, and measure business impact rigorously.
Whether you're looking to accelerate sales cycles through real-time opportunity scoring, improve operational efficiency through predictive maintenance, or enhance customer experience through personalized recommendations, real-time insight loops can transform your business. We invite you to explore how insight loops can compress your decision cycles and unlock competitive advantage. Contact our team to discuss your specific use case and learn how we can help you move from batch analytics to continuous, prescriptive intelligence that drives immediate action and measurable outcomes.
Next step
Book the Opportunity Sprint


